深度强化学习基础¶
深度强化学习(Deep Reinforcement Learning, DRL)是人工智能领域的重要分支,它结合了深度学习的感知能力与强化学习的决策能力,使智能体能通过试错与环境交互,实现自主决策优化。
一、强化学习环境安装¶
学习目标:
1.了解Gymnasium库
2.了解并安装Stable-Baselines3库
3.了解Ray RLlib库
1.1 Gymnasium库¶
Gym是OpenAI团队开发的一个主要针对强化学习实验的开源项目。Gym库内置上百种实验环境,包括以下几类: • 算法环境:包括一些字符串处理等传统计算机算法的实验环境。 • 简单文本环境:包括几个用文本表示的简单游戏。 • 经典控制环境:包括一些简单几何体的运动,常用于经典强化学习算法的研究。 • Atari游戏环境:包括数十个Atari 2600游戏,具有像素化的图形界面,希望玩家尽可能争夺高分。 • 二维方块(Box2D)环境:包括一些连续性控制的任务。 • MuJoCo环境:利用收费的MuJoCo运动引擎进行连续性控制任务。 • 机械控制环境:关于机械臂的抓取和控制等。
Gymnasium 是 OpenAI Gym 的官方维护分支,由 Farama 基金会接管开发(2021年后)。由于原 Gym 库停止更新,Gymnasium 成为强化学习(RL)环境的新标准。Gymnasium提供统一的 RL 环境接口,解决研究中的可复现性和标准化问题,降低算法开发门槛
安装命令(不必安装,下方安装stable-baselines3库会自动安装Gymnasium库)
# 基础库
pip install gymnasium
# 完整依赖(含Atari、Box2D等)
pip install "gymnasium[all]"
1.2 Stable-Baselines3库(SB3)【安装此库】¶
Stable Baselines3(SB3)是一个基于 PyTorch 的强化学习(RL)算法库,旨在提供稳定、易用且高性能的算法实现,适用于学术研究与工业应用。
其代码简洁、易用性高,文档丰富,对于学术研究中一些中小规模的实验以及初学者快速上手强化学习算法而言,是比较好的选择。
-
项目起源
- 源自 OpenAI 的 Baselines 项目,经重构优化后兼容现代深度学习框架(PyTorch)
-
目标
- 降低 RL 实现门槛,避免重复造轮子。
-
优势
- 一简洁的 API:类似 scikit-learn 风格(如
model = PPO("MlpPolicy", env).learn(10000)) - 算法稳定性:严格测试确保结果可复现(如 PPO、DQN 的收敛性)
- 高性能优化:利用 PyTorch 动态计算图加速训练
- 一简洁的 API:类似 scikit-learn 风格(如
-
支持的主流算法
| 算法类型 | 代表性算法 | 适用场景 |
|---|---|---|
| 策略优化类 | PPO, A2C, TRPO | 连续控制(机器人控制) |
| 值函数类 | DQN, QR-DQN | 离散动作(游戏 AI) |
| 混合方法 | SAC, TD3 | 高维状态空间(自动驾驶) |
- 安装命令
# 基础安装(Python ≥3.9, PyTorch ≥2.3)
pip install stable-baselines3
# 完整依赖(含 TensorBoard、OpenCV 等)
pip install stable-baselines3[extra]
1.3 Ray RLlib库¶
Ray 是一个开源的 Python 分布式计算框架。Ray RLlib 是建立在分布式计算框架 Ray 上的强化学习(RL)库,由加州大学伯克利分校 RISELab 开发,旨在提供高性能、可扩展的统一强化学习解决方案。它支持从单机到大规模集群的无缝扩展,广泛应用于游戏 AI、机器人控制、自动驾驶等领域。
-
基于 Ray 的分布式引擎
- 利用 Ray 的分布式任务调度能力,RLlib 可轻松扩展到数千个 CPU/GPU 节点,实现毫秒级任务调度。
-
模块化设计
- 策略(Policy):核心组件,定义智能体行为(如神经网络模型),支持多智能体场景(单一策略或多策略协同)
- 训练器(Trainer):协调分布式工作流,管理策略优化、数据收集和模型更新
-
算法丰富性与兼容性
- 支持 DQN、PPO、A2C、SAC 等 50+ 主流算法
- 兼容 TensorFlow、PyTorch、JAX,用户可自定义模型结构
-
多智能体强化学习(MARL)
- 支持合作、对抗、独立学习等场景,可配置共享或分离的策略网络
-
离线训练与外部集成
- 离线数据集:支持历史数据训练(如工业控制场景)
- 环境兼容:无缝集成 OpenAI Gym、Unity3D、DeepMind OpenSpiel 等环境
-
应用场景
| 场景 | 应用案例 | 技术实现 |
|---|---|---|
| 游戏 AI | Atari 游戏、多智能体对战 | DQN/PPO + 并行环境采样 |
| 机器人控制 | 机械臂路径规划、无人机导航 | SAC/TD3 + 连续动作空间优化 |
| 自动驾驶 | 模拟环境中的决策策略训练 | 多传感器输入(图像+Lidar)的 PPO |
| 资源调度 | 数据中心能耗优化、网络流量控制 | 多智能体协作算法 + 离线数据微调 |
- 安装命令
pip install ray[rllib]
[rllib] 是 “额外依赖组”,会自动安装 RLlib 及强化学习核心依赖(如 gym 基础环境、策略优化相关库 )
二、DQN算法¶
学习目标:
1.理解什么是DQN算法
2.了解DQN算法的基本原理
3.借助sb3库,动手实现DQN算法
2.1 什么是DQN算法¶
在2013 年的NIPS深度学习研讨会上,DeepMind 公司的研究团队发表了DQN 论文,首次展示了这一直接通过卷积神经网络接受像素输入来玩转各种雅达利(Atari)游戏的强化学习算法,由此拉开了深度强化学习的序幕。DQN是深度强化学习的基础,所以有必要首先学习一下该算法。
之前学习的时序差分算法,我们以矩阵的方式建立了一张存储每个状态下所有动作的 Q值的表格。表格中的每一个动作价值Q(s, a) 表示在状态s 下选择动作a 然后继续遵循某一策略预期得到的期望回报。然而,这种用表格存储动作价值的做法只在环境的状态和动作都是离散的,并且空间都比较小的情况下适用。
当状态或者动作数量非常大的时候,这种做法就不适用了。例如,当状态是一张RGB 图像时,假设图像大小是210 ×160 ×3 ,此时一共有256 210×60×3 种状态,在计算机中存储这个数量级的Q 值表格是不现实的。更甚者,当状态或者动作连续的时候,就有无限个状态动作对,我们更加无法使用这种表格形式来记录各个状态动作对的Q值。
对于这种情况,我们需要用函数拟合的方法来估计Q 值,即将这个复杂的Q值表格视作数据,使用一个参数化的函数\(Q_θ\) 来拟合这些数据,DQN算法便可以用来解决连续状态下离散动作的问题。
2.2 车杆环境(CartPole)¶
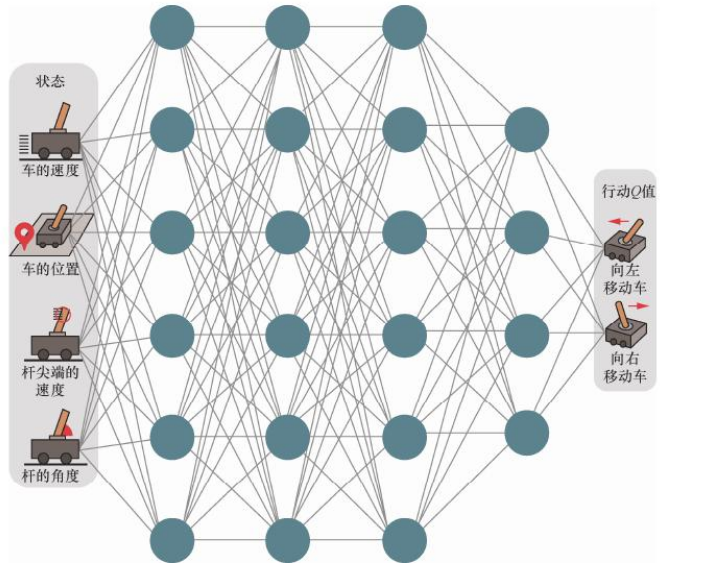
为了学习DQN算法,我们找一个状态值连续、动作值离散的环境-车杆环境。如下图所示

在车杆环境中,有一辆小车,智能体的任务是通过左右移动保持车上的杆竖直,若杆的倾斜度数过大,或者车子离初始位置左右的偏离程度过大,或者坚持时间到达200 帧,则游戏结束。智能体的状态是一个维数为 4 的向量,每一维都是连续的,其动作是离散的,动作空间大小为2。在游戏中每坚持一帧,智能体能获得分数为1 的奖励,坚持时间越长,则最后的分数越高,坚持 200 帧即可获得最高的分数。

2.3 DQN算法基本原理¶
在类似车杆的环境中得到动作价值函数Q(s, a) ,由于状态每一维度的值都是连续的,无法使用表格记录,因此一个常见的解决方法便是使用函数拟合(function approximation)的思想。
由于神经网络具有强大的表达能力,因此我们可以用一个神经网络来表示函数Q 。若动作是连续(无限)的,神经网络的输入是状态s 和动作 a,然后输出一个标量,表示在状态s下采取动作a 能获得的价值。若动作是离散(有限)的,除了可以采取动作连续情况下的做法,我们还可以只将状态s输入到神经网络中,使其同时输出每一个动作的Q 值。
通常 DQN(以及 Q-learning)只能处理动作离散的情况,因为在函数Q 的更新过程中有\(\max_a\) 这一操作。假设神经网络用来拟合函数Q 的参数是ω,即每一个状态s 下所有可能动作 a的 Q值都能表示为\(Q_\omega(s, a)\) 。我们将用于拟合函数Q 的神经网络称为Q网络,如下图所示:
接下来思考一下,Q网络的损失函数该如何定义。我们先来回顾一下Q-learning的更新规则
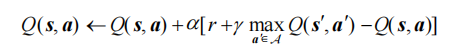
上述公式用时序差分(temporal difference,TD)学习目标\(r + \gamma \max_{a'} Q(s', a')\) 来增量式更新 Q(s, a),也就是说要使 Q(s, a)向 TD 误差目标\(r + \gamma \max_{a'} Q(s', a')\)靠近。于是,对于一组数据{(s, a, r, s')},我们可以将Q 网络的损失函数构造为均方误差的形式:
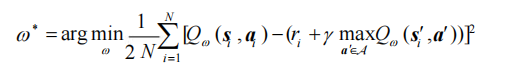
至此,我们就可以将Q-learning 扩展到神经网络形式——深度 Q 网络(deep Q network,DQN)算法。
DQN 是离线策略算法,因此我们在收集数据的时候可以使用一个ε -贪婪策略来平衡探索与利用,将收集到的数据存储起来,在后续的训练中使用。DQN中还有两个非常重要的模块—经验回放和目标网络,它们能够帮助 DQN 取得稳定、出色的性能。
2.3.1 经验回放¶
在一般的有监督学习中,假设训练数据是独立同分布的,我们每次训练神经网络的时候从训练数据中随机采样一个或若干个数据来进行梯度下降,随着学习的不断进行,每一个训练数据会被使用多次。在原来的 Q-learning算法中,每一个数据只会用来更新一次Q 值。
为了更好地将 Q-learning和深度神经网络结合,DQN 算法采用了经验回放(experience replay)方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练。
经验回放可以起到以下两个作用:
- 使样本满足独立假设。在MDP 中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态和上一时刻的状态有关。非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上。采用经验回放可以打破样本之间的相关性,让其满足独立假设;
- 提高样本效率。每一个样本可以被使用多次,十分适合深度神经网络的梯度学习。
2.3.2 目标网络¶
DQN 算法最终更新的目标是让\(Q_\omega(s, a)\) 逼近\(r + \gamma \max_{a'} Q(s', a')\),由于 TD 误差目标本身就包含神经网络的输出,因此在更新网络参数的同时目标也在不断地改变,这非常容易造成神经网络训练的不稳定性。
为了解决这一问题,DQN 便使用了目标网络( target network)的思想:既然在训练过程中 Q 网络的不断更新会导致目标不断发生改变,不如暂时先将TD 误差目标中的 Q 网络固定住。为了实现这一思想,我们需要利用两套Q网络。
- 原来的训练网络\(Q_\omega(s, a)\),用于计算原来的损失函数\(\frac{1}{2} \left[ Q_\omega(s, a) - \left( r + \gamma \max_{a'} Q_{\omega^-}(s', a') \right) \right]^2\)中的 \(Q_\omega(s, a)\)项,并且使用正常梯度下降方法来进行更新。
- 目标网络\(Q_{\omega^-}(s, a)\),用于计算原来的损失函数\(\frac{1}{2} \left[ Q_\omega(s, a) - \left( r + \gamma \max_{a'} Q_{\omega^-}(s', a') \right) \right]^2\)中的\(r + \gamma \max_{a'} Q_{\omega^-}(s', a')\)项,其中\(\omega^-\)表示目标网络中的参数。
如果两套网络的参数随时保持一致,则仍为原来不够稳定的算法。为了让更新目标更稳定,目标网络并不会每一步都更新。具体而言,目标网络使用训练网络的一套比较旧的参数,训练网络\(Q_\omega(s, a)\)在训练中的每一步都会更新,而目标网络的参数每隔 C步才会与训练网络同步一次,即\(\omega^- \leftarrow \omega\)。这样做使得目标网络相对于训练网络更加稳定。
综上,DQN 算法的具体流程如下:

2.4 基于Stable-Baselines3实现DQN¶
实现步骤:
-
导入库
-
创建环境
-
创建DQN模型
-
定义自定义回调函数类
-
实例化回调函数对象
-
训练模型,传入回调函数
-
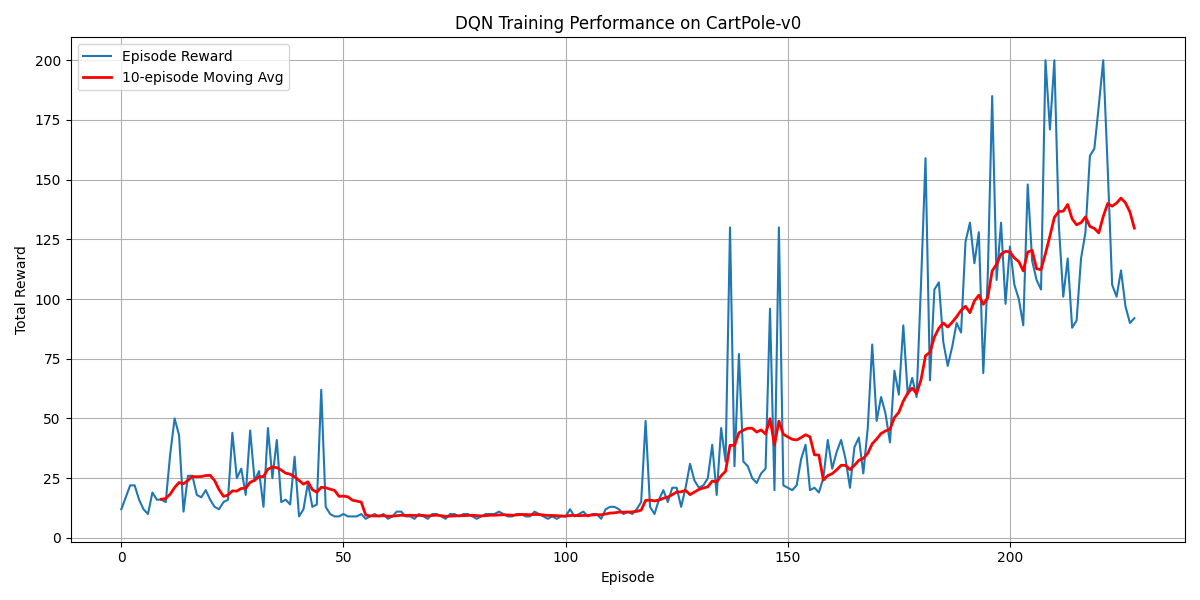
训练完成后,绘制episode_rewards曲线
# -*- coding: utf-8 -*-
import gymnasium as gym # Gymnasium 环境库
from stable_baselines3 import DQN # Stable Baselines3 中的 DQN 算法
from stable_baselines3.common.callbacks import BaseCallback # 自定义回调函数基类
import matplotlib.pyplot as plt # 数据可视化库
import numpy as np # 数值计算库
# 自定义回调函数用于记录每个 episode 的回报
class RewardLogger(BaseCallback):
"""
BaseCallback 是 Stable Baselines3 提供的回调函数基类,它定义了回调函数的基本结构和接口规范
所以需要继承并实现必要的方法
在训练过程中记录每个 episode 的总奖励。
"""
def __init__(self, verbose=0):
super(RewardLogger, self).__init__(verbose)
self.episode_rewards = [] # 存储每个 episode 的总奖励
self.current_episode_reward = 0 # 当前 episode 的累计奖励
def _on_step(self) -> bool:
"""
_on_step(): 每个时间步都会调用,必须实现
每一步都会调用此方法,累加当前 episode 的奖励。
如果 episode 结束,则保存当前 episode 的总奖励。
"""
# self.locals 是 BaseCallback 类中的一个重要属性,在每次调用 _on_step() 方法时自动更新
# self.locals 是一个字典,包含当前时间步的信息,如状态、动作、奖励、是否结束等
# self.locals['rewards'] 是一个列表,包含当前时间步的奖励
# self.locals['dones'] 是一个列表,包含当前时间步的结束标志
reward = self.locals['rewards'][0] # 获取当前步的奖励
self.current_episode_reward += reward
# 如果当前 episode 结束
if self.locals['dones'][0]:
self.episode_rewards.append(self.current_episode_reward)
self.current_episode_reward = 0 # 重置当前 episode 奖励
return True # 返回 True 表示继续训练
# 创建环境和模型
env = gym.make('CartPole-v0') # 使用 CartPole-v0 环境
# 初始化 DQN 模型
model = DQN(
'MlpPolicy', # 使用多层感知机策略(适用于低维状态空间)
env, # 绑定的 Gymnasium 环境
learning_rate=2e-3, # 学习率
batch_size=64, # 训练时每次采样的批次大小
buffer_size=20000, # 经验回放缓冲区容量
learning_starts=1000, # 开始学习前的随机探索步数
target_update_interval=100, # 更新目标网络的频率(步数)
gamma=0.98, # 折扣因子
verbose=1 # 打印训练日志
)
# 初始化回调函数
reward_logger = RewardLogger()
# 开始训练模型,设置总步数为 10000 步,具体的 episode 数量是由环境中自动完成的。
# 每当一次 episode 结束(即 done=True),就会开始一个新的 episode,直到累计达到 10000 步为止。
model.learn(total_timesteps=10000, callback=reward_logger)
# 绘制回报曲线
plt.figure(figsize=(12, 6))
print(reward_logger.episode_rewards)
print(type(reward_logger.episode_rewards))
print(len(reward_logger.episode_rewards))
plt.plot(reward_logger.episode_rewards, label='Episode Reward')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('DQN Training Performance on CartPole-v0')
plt.grid(True)
# 添加移动平均线(窗口大小为10)
window_size = 10
moving_avg = np.convolve(reward_logger.episode_rewards,
np.ones(window_size) / window_size,
mode='valid')
# 移动平均线从第 window_size 个 episode 开始绘制
plt.plot(range(window_size - 1, len(reward_logger.episode_rewards)),
moving_avg,
'r-',
linewidth=2,
label=f'{window_size}-episode Moving Avg')
plt.legend()
plt.tight_layout()
# 保存图像到本地
plt.savefig('dqn_cartpole_rewards.png', dpi=300)
# 显示图像
plt.show()
2.5 DQN算法底层实现【了解】¶
测试环境是CartPole-v0,其状态空间相对简单,只有 4 个变量,因此网络结构的设计也相对简单:采用一层128 个神经元的全连接并以 ReLU 作为激活函数。当遇到更复杂的诸如以图像作为输入的环境时,我们可以考虑采用深度卷积神经网络。
- 网络定义
# -*- coding: utf-8 -*-
import random
import gymnasium as gym
import numpy as np # 数值计算库
import collections # 提供常用数据结构(如 deque)
from tqdm import tqdm # 显示进度条的库
import torch # PyTorch 深度学习框架
import torch.nn.functional as F # 神经网络函数模块
import matplotlib.pyplot as plt # 数据可视化库
class ReplayBuffer:
"""
经验回放池:用于存储智能体与环境交互的历史经验,并从中随机采样小批量数据进行训练。
"""
def __init__(self, capacity):
""" deque是一个类似于列表(list - like)的序列,但针对在其端点附近进行数据访问进行了优化
deque(全称double - ended queue,这意味着你可以在序列的左端和右端都进行高效的添加和删除操作。
它与普通列表(list)最大的区别在于性能。对于列表,在开头插入或删除元素(insert(0, v)或
pop(0))的时间复杂度是O(n),因为需要移动所有其他元素。而deque在两端进行添加和删除操作的时间复杂度都是
O(1),非常高效"""
self.buffer = collections.deque(maxlen=capacity) # 使用双端队列存储经验
def add(self, state, action, reward, next_state, done):
"""
添加一条经验到缓冲池中。
参数:
state: 当前状态
action: 执行的动作
reward: 获得的奖励
next_state: 下一状态
done: 是否结束标志
"""
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
"""
随机采样一个批次的经验数据。
参数:
batch_size: 批量大小
返回:
states: 状态数组
actions: 动作数组
rewards: 奖励数组
next_states: 下一状态数组
dones: 结束标志数组
"""
transitions = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*transitions)
return np.array(state), action, reward, np.array(next_state), done
def size(self):
"""
获取当前缓冲池中存储的经验数量。
"""
return len(self.buffer)
class Qnet(torch.nn.Module):
"""
只有一层隐藏层的Q网络,用于估计每个动作的价值。
输入:state_dim -> 状态维度
hidden_dim -> 隐藏层维度
action_dim -> 动作维度
输出:每个动作的Q值
"""
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 第一层全连接
self.fc2 = torch.nn.Linear(hidden_dim, action_dim) # 第二层全连接
def forward(self, x):
x = F.relu(self.fc1(x)) # 使用 ReLU 激活函数
return self.fc2(x) # 输出每个动作的 Q 值
class DQN:
"""
DQN 算法实现类,包含策略网络、目标网络、更新规则等。
"""
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
epsilon, target_update, device):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device) # Q网络
self.target_q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device) # 目标网络
self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=learning_rate) # Adam优化器
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # 探索率(epsilon-greedy)
self.target_update = target_update # 目标网络更新频率
self.count = 0 # 更新计数器
self.device = device # 设备(CPU or GPU)
def take_action(self, state):
"""
使用 epsilon-greedy 策略选择动作。
参数:
state: 当前状态
返回:
action: 选择的动作编号
"""
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def update(self, transition_dict):
"""
使用经验数据更新 Q 网络。
参数:
transition_dict: 包含 states, actions, rewards, next_states, dones 的字典
"""
# 将经验数据转换为 tensor 并移动到指定设备
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
# 计算当前 Q 值:根据 actions 中对应的索引值,从 q_values 中提取该动作对应的 Q 值,最终得到一个形状为 [batch_size, 1] 的张量
"""
示例:# Q网络对所有动作的预测值 (shape: [2, 3])
# 状态1: 动作0的Q=0.1, 动作1的Q=0.5, 动作2的Q=0.3
# 状态2: 动作0的Q=0.2, 动作1的Q=0.4, 动作2的Q=0.6
q_net_output = torch.tensor([[0.1, 0.5, 0.3],
[0.2, 0.4, 0.6]])
# 实际采取的动作索引 (shape: [2, 1])
actions = torch.tensor([[1], # 在状态1采取了动作1
[2]]) # 在状态2采取了动作2
# 使用gather提取对应动作的Q值
q_values = q_net_output.gather(1, actions)
print(q_values)
# 输出: tensor([[0.5], # 对应状态1的动作1的Q值
# [0.6]]) # 对应状态2的动作2的Q值
"""
q_values = self.q_net(states).gather(1, actions)
# 使用目标网络计算下一状态的最大 Q 值
"""
target_q_net网络结构与q_net一样,输出形状为[batch_size, action_dim],表示每个状态下所有动作的Q值
.max(1)是在第一个维度(动作维度)寻找最大值,返回一个元组:(最大值,对应的索引)
[0]表示取元组中最大值部分,丢弃索引
.view(-1, 1),将结果重塑为列向量形式,形状为 [batch_size, 1]
"""
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)
# TD error 目标
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones)
# 计算均方误差损失
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets))
# 反向传播更新参数
self.optimizer.zero_grad()
dqn_loss.backward()
self.optimizer.step()
# 定期更新目标网络
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(self.q_net.state_dict())
self.count += 1
- 模型训练
# 设置超参数
lr = 2e-3 # 学习率
num_episodes = 500 # 总共训练的回合数
hidden_dim = 128 # 网络隐藏层大小
gamma = 0.98 # 折扣因子
epsilon = 0.01 # 探索率
target_update = 10 # 目标网络更新频率
buffer_size = 10000 # 经验回放缓冲区大小
minimal_size = 500 # 开始训练前需要的最小经验数量
batch_size = 64 # 每次训练使用的经验批大小
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# 创建环境
env_name = 'CartPole-v0'
env = gym.make(env_name)
random.seed(0)
np.random.seed(0)
env.action_space.seed(0)
torch.manual_seed(0)
# 初始化经验回放缓冲区
replay_buffer = ReplayBuffer(buffer_size)
# 获取状态空间和动作空间维度
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 实例化 DQN 算法对象
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon, target_update, device)
# 记录每个 episode 的回报
return_list = []
# 开始训练
for i in range(10): # 分批次显示进度条
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个批次的 episode 数量
episode_return = 0 # 当前 episode 的总回报
state, _ = env.reset() # 环境重置
done = False # 是否结束标志
# 运行单个 episode
while not done:
action = agent.take_action(state) # 采样动作
next_state, reward, terminated, truncated, _ = env.step(action) # 执行动作
done = terminated or truncated # 合并两个条件作为 done 标志
# 存储轨迹数据
replay_buffer.add(state, action, reward, next_state, done)
state = next_state # 更新状态
episode_return += reward # 累计奖励
# 当 buffer 数据足够时,开始训练
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones': b_d
}
agent.update(transition_dict)
return_list.append(episode_return) # 保存 episode 回报
# 每 10 个 episode 打印一次平均回报
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])
})
pbar.update(1) # 更新进度条
def moving_average(a, window_size):
"""
计算数组的滑动平均值
Args:
a (array-like): 输入数组
window_size (int): 滑动窗口大小
Returns:
numpy.ndarray: 滑动平均后的数组
"""
# 计算累积和,在数组开头插入0以便计算
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
# 计算中间部分的滑动平均值
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
# 处理边界情况
r = np.arange(1, window_size - 1, 2)
# 计算起始部分的滑动平均值
begin = np.cumsum(a[:window_size - 1])[::2] / r
# 计算结束部分的滑动平均值
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
# 拼接三部分结果
return np.concatenate((begin, middle, end))
# 绘图展示训练过程中的回报曲线
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
# 绘制滑动平均回报曲线
mv_return = moving_average(return_list, 9) # 9点滑动平均
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
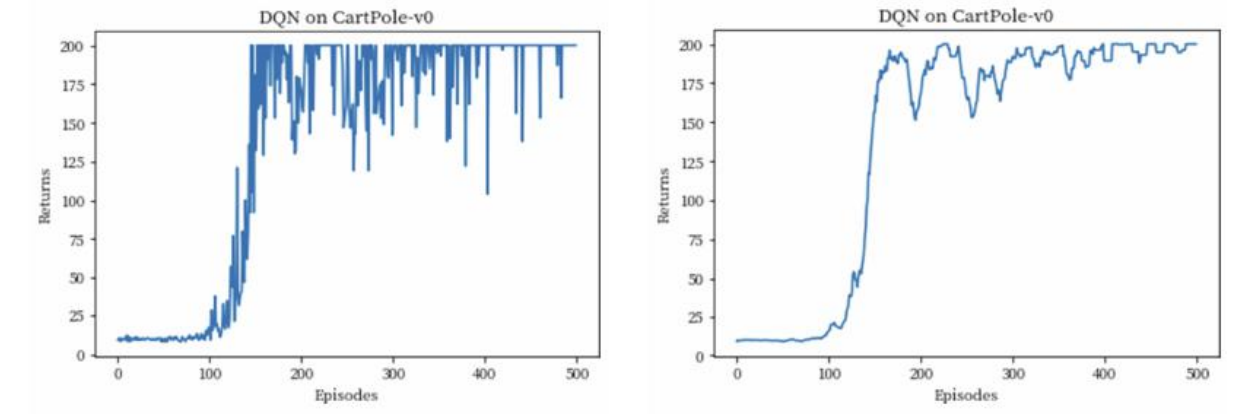
可以看到,DQN 的性能在 100个序列后很快得到提升,最终收敛到策略的最优回报值200。
三、策略梯度算法¶
学习目标:
1.理解基于策略的方法
2.了解REINFORCE算法基本原理
3.1 策略梯度¶
之前介绍的Sarsa、Q-learning以及DQN 算法都是基于价值(value-based)的方法,其中 Q-learning是处理有限状态的算法,而 DQN 可以用来解决连续状态的问题。所用到的是函数逼近的思想。
在强化学习中,除了将函数逼近思想应用于表示状态/动作价值,还可以应用于表示策略。
当策略由函数表示时,可以通过优化某些标量指标(scalar metrics)来获得最优策略。这种方法被称为策略梯度(policy gradient)方法。它在处理大的状态/动作空间时效率更高,且具有更强的泛化能力。
策略梯度方法的基本思想总结如下。假设 \(J(\theta)\) 是一个标量指标。最优策略可以通过基于梯度的算法优化该指标来获得:
其中 \(\nabla_\theta J\) 是 \(J\) 关于 \(\theta\) 的梯度,\(t\) 是时间步,\(\alpha\) 是优化率(学习率)。
这个迭代公式非常眼熟,是梯度上升的迭代公式,与我们非常熟悉的梯度下降法的迭代公式只差了一个正负号。
假设目标策略 \(\pi_\theta\) 是一个随机性策略,并且处处可微,其中 θ是对应的参数。我们可以用一个线性模型或者神经网络模型来为这样一个策略函数建模,输入某个状态,然后输出一个动作的概率分布。
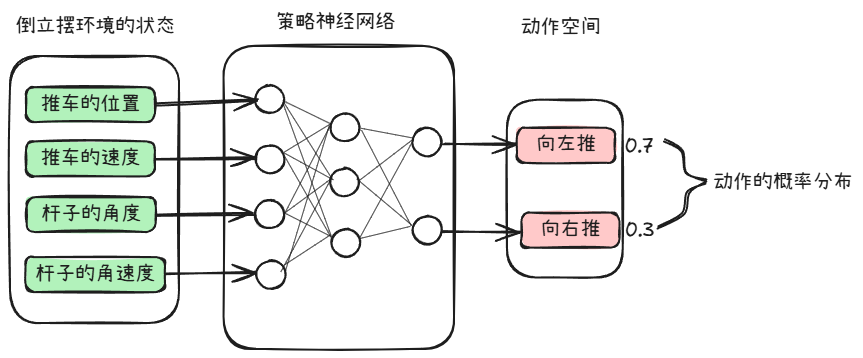
我们的目标是寻找一个最优策略并最大化这个策略在环境中的期望回报。
3.2 目标函数¶
有了策略梯度的思想,接下来的任务就是设计出目标函数。有两种方式,一种是基于状态价值,另一种是基于即时奖励。
- 平均状态价值(平均价值)
其中 \(d(s)\) 是状态 \(s\) 的权重。它满足对于任意 \(s \in \mathcal{S}\),\(d(s) \ge 0\) 且 \(\sum_{s \in \mathcal{S}} d(s) = 1\)。因此,我们可以将 \(d(s)\) 解释为 \(s\) 的概率分布。那么,该指标可以写成:
顾名思义,\(\bar{v}_\pi\) 是状态价值的加权平均。不同的 \(\theta\) 值导致不同的 \(\bar{v}_\pi\) 值。我们的最终目标是找到一个最优策略(或者等价地,一个最优的 \(\theta\))来最大化 \(\bar{v}_\pi\)。
- 平均单步奖励(平均奖励)
其中 \(d_\pi\) 是平稳分布。
虽然给出了两种目标函数,但 \(\bar{v}_\pi\) 和 \(\bar{r}_\pi\) 在折扣因子 \(\gamma < 1\) 的情况下是等价的。特别地,可以证明
\(\bar{r}_\pi = (1 - \gamma)\bar{v}_\pi\)
因此选用哪一个目标函数来使用基于梯度的方法来最大化它们,进而得到最终的策略都是可以的。
3.3 策略梯度定理¶
有了目标函数,再计算出目标函数对策略函数的参数\(\theta\)的梯度,就可以用梯度上升法来求解了。
梯度的推导是策略梯度方法中最复杂的部分,这里直接给出策略梯度定理,不再进行推导了。
\(J(\theta)\) 的梯度是 $$ \nabla_\theta J(\theta) = \sum_{s \in \mathcal{S}} \eta(s) \sum_{a \in \mathcal{A}} \nabla_\theta \pi(a|s, \theta) q_\pi(s, a), \quad (3.1) $$ 其中 \(\eta\) 是一个状态分布,\(\nabla_\theta \pi\) 是 \(\pi\) 关于 \(\theta\) 的梯度。此外,(3.1) 有一个用期望表示的紧凑形式:
其中 \(\ln\) 是自然对数。
3.4 REINFORCE算法(了解)¶
有了定理 3.2 中给出的梯度,我们接下来展示如何使用基于梯度的方法来优化指标以获得最优策略。
由于 (3.2) 中的真实梯度是未知的,我们可以用随机梯度代替真实梯度,得到以下算法: $$ \theta_{t+1} = \theta_t + \alpha \nabla_\theta \ln \pi(a_t|s_t, \theta_t) q_t(s_t, a_t), \quad (3.3) $$ 其中 \(q_t(s_t, a_t)\) 是 \(q_\pi(s_t, a_t)\) 的近似值,是通过蒙特卡洛估计获得的,即: $$ q_t(s_t, a_t) \approx G_t= \sum_{k=t+1}^T \gamma^{k-t-1} r_k $$ 其中 Gt是从时刻 t开始的回报,γ是折扣因子。
该算法称为 REINFORCE或 蒙特卡洛策略梯度(Monte Carlo policy gradient),这是最早和最简单的策略梯度算法之一。
REINFORCE算法的核心思想是:我们不需要知道或学习一个 Q函数,而是可以直接通过采样一整条轨迹,用实际观测到的、从 t时刻开始的累计回报 Gt来作为\(Q^{\pi^\theta}(s_t, a_t)\)的无偏估计。
算法更新步骤:
初始化: 初始参数 \(\theta\);\(\gamma \in (0, 1)\);\(\alpha > 0\)。
目标: 学习一个最优策略以最大化 \(J(\theta)\)。
对于每一回合 (episode),做
生成一回合 \(\{s_0, a_0, r_1, \dots, s_{T-1}, a_{T-1}, r_T\}\) 跟随 \(\pi(\theta)\)。
对于 \(t = 0, 1, \dots, T-1\):
价值更新: \(q_t(s_t, a_t) = \sum_{k=t+1}^T \gamma^{k-t-1} r_k\)
策略更新: \(\theta \leftarrow \theta + \alpha \nabla_\theta \ln \pi(a_t|s_t, \theta) q_t(s_t, a_t)\)
3.5 REINFORCE算法底层实现【了解】¶
我们在车杆环境中实现REINFORCE算法
- 定义策略网络
# 引入必要的库
import gym # OpenAI Gym 环境库
import torch # PyTorch 深度学习框架
import torch.nn.functional as F # 神经网络函数模块
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 数据可视化库
from tqdm import tqdm # 显示进度条的库
# 定义策略网络 PolicyNet
class PolicyNet(torch.nn.Module):
"""
策略网络,用于输出状态下的动作概率分布。
输入:state_dim -> 状态维度
hidden_dim -> 隐藏层维度
action_dim -> 动作维度
输出:softmax 归一化的动作概率分布
"""
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 第一层全连接
self.fc2 = torch.nn.Linear(hidden_dim, action_dim) # 第二层全连接
def forward(self, x):
x = F.relu(self.fc1(x)) # 使用 ReLU 激活函数
return F.softmax(self.fc2(x), dim=1) # 使用 softmax 输出动作概率分布
- 定义 REINFORCE 算法。在 take_action()函数中,我们通过动作概率分布对离散的动作进行采样。在更新过程中,我们按照算法将损失函数写为策略回报的负数,即
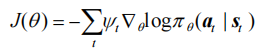
对θ求导后就可以通过梯度下降来更新策略。
# REINFORCE 算法实现类
class REINFORCE:
"""
REINFORCE 算法:基于策略梯度的强化学习方法。
"""
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, device):
self.policy_net = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
# 使用 Adam 优化器更新策略网络参数
self.optimizer = torch.optim.Adam(self.policy_net.parameters(), lr=learning_rate)
self.gamma = gamma # 折扣因子
self.device = device # 设备选择(CPU 或 GPU)
def take_action(self, state):
"""
根据当前状态采样一个动作(使用分类分布进行随机采样)。
"""
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.policy_net(state) # 获取当前状态的动作概率分布
action_dist = torch.distributions.Categorical(probs) # 构造分类分布
action = action_dist.sample() # 采样动作
return action.item() # 返回动作编号
def update(self, transition_dict):
"""
使用轨迹数据对策略网络进行更新。
"""
reward_list = transition_dict['rewards']
state_list = transition_dict['states']
action_list = transition_dict['actions']
G = 0 # 初始化回报 G_t
self.optimizer.zero_grad() # 清空梯度
# 从后往前遍历每一步的轨迹数据(MC 方法)
for i in reversed(range(len(reward_list))):
reward = reward_list[i]
state = torch.tensor([state_list[i]], dtype=torch.float).to(self.device)
action = torch.tensor([action_list[i]]).view(-1, 1).to(self.device)
probs = self.policy_net(state) # 获取状态对应的动作概率
log_prob = torch.log(probs.gather(1, action)) # 计算 log π(a|s)
G = self.gamma * G + reward # 累积折扣回报
loss = -log_prob * G # 策略梯度损失函数
loss.backward() # 反向传播计算梯度
self.optimizer.step() # 更新网络参数(梯度下降)
- 模型训练,查看REINFORCE算法在车杆环境上的表现
# 设置超参数
learning_rate = 1e-3 # 学习率
num_episodes = 1000 # 总共训练的回合数
hidden_dim = 128 # 网络隐藏层大小
gamma = 0.98 # 折扣因子
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# 创建环境
env_name = "CartPole-v0" # CartPole 环境
env = gym.make(env_name) # 初始化环境
env.action_space.seed(0) # 固定种子以保证实验可复现
torch.manual_seed(0) # 固定 PyTorch 的随机种子
# 获取状态空间和动作空间维度
state_dim = env.observation_space.shape[0] # 状态维度
action_dim = env.action_space.n # 动作数量
# 实例化 REINFORCE 算法对象
agent = REINFORCE(state_dim, hidden_dim, action_dim, learning_rate, gamma, device)
# 记录每个 episode 的回报
return_list = []
# 开始训练
for i in range(10): # 分批次显示进度条
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个批次的 episode 数量
episode_return = 0 # 当前 episode 的总回报
transition_dict = { # 存储单次 episode 的轨迹数据
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': []
}
state, _ = env.reset() # 环境重置
done = False # 是否结束标志
# 运行单个 episode
while not done:
action = agent.take_action(state) # 采样动作
next_state, reward, terminated, truncated, _ = env.step(action) # 执行动作
done = terminated or truncated # 合并两个条件作为 done 标志
# 存储轨迹数据
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state # 更新状态
episode_return += reward # 累计奖励
return_list.append(episode_return) # 保存 episode 回报
agent.update(transition_dict) # 更新策略网络
# 每 10 个 episode 打印一次平均回报
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])
})
pbar.update(1) # 更新进度条
def moving_average(a, window_size):
"""
计算数组的滑动平均值
Args:
a (array-like): 输入数组
window_size (int): 滑动窗口大小
Returns:
numpy.ndarray: 滑动平均后的数组
"""
# 计算累积和,在数组开头插入0以便计算
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
# 计算中间部分的滑动平均值
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
# 处理边界情况
r = np.arange(1, window_size - 1, 2)
# 计算起始部分的滑动平均值
begin = np.cumsum(a[:window_size - 1])[::2] / r
# 计算结束部分的滑动平均值
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
# 拼接三部分结果
return np.concatenate((begin, middle, end))
# 绘图展示训练过程中的回报曲线
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()
# 绘制滑动平均回报曲线
mv_return = rl_utils.moving_average(return_list, 9) # 9点滑动平均
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('REINFORCE on {}'.format(env_name))
plt.show()
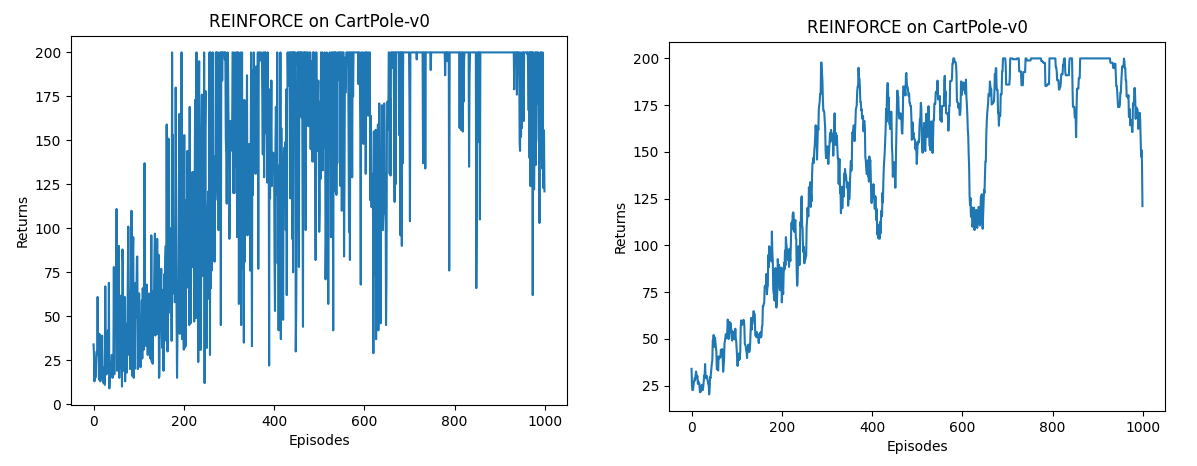
四、Actor-Critic架构¶
学习目标:
1.理解Actor-Critic的含义
2.知道Actor-Critic实现流程
4.1 Actor-Critic介绍¶
前边学习了基于值函数的方法(DQN)和基于策略的方法(REINFORCE),基于值函数的方法只学习一个价值函数,而基于策略的方法只学习一个策略函数。那么,一个很自然的问题是,有没有什么方法既学习价值函数,又学习策略函数呢?
“Actor-Critic”是一种结合了基于策略和基于价值方法的结构。在这里,“Actor(演员)”指的是策略更新步骤。之所以称之为演员,是因为动作是由该策略执行的。而“Critic(评论家)”指的是价值更新步骤。之所以称之为评论家,是因为它通过评估相应的价值来批评(评价)演员的表现。Actor-Critic是囊括一系列算法的整体架构,目前很多高效的前沿算法都属于Actor-Critic算法。
我们将Actor-Critic分为两个部分:Actor(策略网络)和Critic(价值网络)。
- Actor (演员)
- 与环境交互,并在 Critic 价值函数的指导下用策略梯度学习一个更好的策略。
- Critic(评论家)
- 通过 Actor 与环境交互收集的数据学习一个动作价值函数q(s,a),这个价值函数会用于判断在当前状态什么动作是好的,什么动作不是好的,进而帮助Actor 进行策略更新。

回顾公式3.3 $$ \theta_{t+1} = \theta_t + \alpha \nabla_\theta \ln \pi(a_t|s_t, \theta_t) q_t(s_t, a_t), \quad (3.3) $$ 该公式清晰地展示了如何结合基于策略和基于价值的方法。一方面,它是一个基于策略(policy-based)的算法,因为它直接更新策略参数。另一方面,该方程需要知道 \(q_t(s_t, a_t)\),这是对动作价值 \(q_\pi(s_t, a_t)\) 的估计。因此,需要另一个基于价值(value-based)的算法来生成 \(q_t(s_t, a_t)\)。到目前为止,我们在本书中学习了两种估计动作价值的方法。第一种是基于蒙特卡洛(Monte Carlo)学习,第二种是基于时序差分(TD)学习。
- 如果 \(q_t(s_t, a_t)\) 是通过蒙特卡洛学习估计的,相应的算法称为 REINFORCE 或 蒙特卡洛策略梯度,这在上一节中已经介绍过。
- 如果 \(q_t(s_t, a_t)\) 是通过 TD 学习估计的,相应的算法通常称为 Actor-Critic。因此,Actor-Critic 方法可以通过将基于 TD 的价值估计融入策略梯度方法中获得。
Actor-Critic算法的基础流程如下:
初始化: 策略函数 \(\pi(a|s, \theta_0)\),其中 \(\theta_0\) 是初始参数。价值函数 \(q(s, a, w_0)\),其中 \(w_0\) 是初始参数。学习率 \(\alpha_w, \alpha_\theta > 0\)。 目标: 学习一个最优策略以最大化 \(J(\theta)\)。
在每一回合(episode)的每个时间步 \(t\):
-
根据 \(\pi(a|s_t, \theta_t)\) 生成 \(a_t\),观察 \(r_{t+1}, s_{t+1}\),然后根据 \(\pi(a|s_{t+1}, \theta_t)\) 生成 \(a_{t+1}\)。
-
Actor (策略更新): $$ \theta_{t+1} = \theta_t + \alpha_\theta \nabla_\theta \ln \pi(a_t | s_t, \theta_t) q(s_t, a_t, w_t) $$
其中:
-
\(\theta\) (Theta): Actor 网络的参数
- \(\theta_t\):当前时刻(更新前)策略神经网络的权重和偏置。
- \(\theta_{t+1}\):更新后的参数。我们的目标就是不断调整 \(\theta\),让策略越来越好。
-
\(\alpha_\theta\) (Alpha_theta): Actor 的学习率 (Learning Rate)
- 控制参数更新步长的大小。注意这里下标是 \(\theta\),表示这是专门用于 Actor 网络的学习率,通常与 Critic 的学习率 (\(\alpha_w\)) 不同。
-
\(\pi(a_t|s_t, \theta_t)\) : 策略函数 (Policy Function)
- 这是 Actor 网络的核心输出。它表示在参数为 \(\theta_t\) 的情况下,处于状态 \(s_t\) 时,选择动作 \(a_t\) 的概率。
-
\(\ln \pi(a_t|s_t, \theta_t)\) : 对数概率 (Log Probability)
- 我们对概率取自然对数。
- 为什么要取对数?
- 数学方便:在求导时,对数函数能将乘法变为加法,且 \(\nabla \ln x = \frac{1}{x} \nabla x\),这在推导策略梯度定理时非常关键。
- 数值稳定:概率值通常很小(0到1之间),连乘容易导致数值下溢(变成0),取对数可以将数值范围扩展到负无穷到0,计算更稳定。
-
\(\nabla_\theta \ln \pi(a_t|s_t, \theta_t)\) : 分数函数/对数概率梯度 (Score Function)
- 这是整个公式的“方向盘”。
- 它告诉我们:如果要提高动作 \(a_t\) 被选中的概率,参数 \(\theta\) 应该往哪个方向调整。
- 如果只顺着这个梯度走,网络就会无脑地增加当前动作 \(a_t\) 的概率。
-
\(q(s_t, a_t, w_t)\) : 动作价值 (Action Value) —— 来自 Critic
- 这是 Critic 网络根据参数 \(w_t\) 计算出的评价。
- 它代表了:在状态 \(s_t\) 下,采取动作 \(a_t\) 到底有多好(期望回报是多少)。
- 在这个公式中,它充当了“权重”或“标量乘子”的角色。
3 Critic (价值更新):
Critic 的目标是让预测值 \(q(s_t, a_t, w)\) 尽可能接近真实的回报期望。在时序差分(TD)学习中,我们没有真实的“标签”,而是用 TD Target 作为临时的标签。
定义平方误差损失函数 \(L(w)\):
\(L(w) = \frac{1}{2} \left( \underbrace{r_{t+1} + \gamma q(s_{t+1}, a_{t+1}, w_{old})}_{\text{TD Target}} - \underbrace{q(s_t, a_t, w)}_{\text{当前预测}} \right)^2\)
损失函数对参数w求梯度,进而得到Critic的参数迭代公式:
$$ w_{t+1} = w_t + \alpha_w [r_{t+1} + \gamma q(s_{t+1}, a_{t+1}, w_t) - q(s_t, a_t, w_t)] \nabla_w q(s_t, a_t, w_t) $$
其中:
- \(w\) (Weight): Critic 网络的参数(权重)。
- \(w_t\):当前时刻(更新前)的参数。
- \(w_{t+1}\):下一时刻(更新后)的参数。
- \(\alpha_w\) (Learning Rate): Critic 的学习率。它控制每次参数更新的步长。如果太大,网络可能震荡;如果太小,收敛速度会很慢。
- \(r_{t+1}\) (Reward): 在状态 \(s_t\) 执行动作 \(a_t\) 后,环境反馈的即时奖励。
- \(\gamma\) (Gamma): 折扣因子(Discount Factor),范围在 \([0, 1]\) 之间。用于衡量未来奖励对当前价值的影响程度。
- \(q(s, a, w)\) (Action-Value Function): 近似动作价值函数。它是一个由参数 \(w\) 定义的函数(例如神经网络),输入状态 \(s\) 和动作 \(a\),输出该状态动作对的预估价值。
- TD 目标 (TD Target): \(r_{t+1} + \gamma q(s_{t+1}, a_{t+1}, w_t)\)
- 这是基于真实奖励 \(r_{t+1}\) 和对下一时刻价值的估计 \(\gamma q(...)\) 组成的“更准确的估计值”。
- TD 误差 (TD Error): \([r_{t+1} + \gamma q(s_{t+1}, a_{t+1}, w_t) - q(s_t, a_t, w_t)]\)
- 这是 “目标值” 减去 “当前预测值”。
- 如果该值为正,说明当前的 \(q(s_t, a_t)\) 估低了(实际结果比预想的好);如果为负,说明估高了。
- \(\nabla_w q(s_t, a_t, w_t)\) (Gradient): 价值函数 \(q\) 关于参数 \(w\) 的梯度。
- 它指明了参数 \(w\) 应该向哪个方向变化,才能使输出的 \(q\) 值增加。
4.2 Actor-Critic 算法底层实现【了解】¶
# -*- coding: utf-8 -*-
from tqdm import tqdm
import gymnasium as gym # Gymnasium 环境库(推荐用于新项目)
import torch # PyTorch 深度学习框架
import torch.nn.functional as F # 神经网络函数模块
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 数据可视化库
# 定义策略网络 PolicyNet(继承自 PyTorch Module)
class PolicyNet(torch.nn.Module):
"""
策略网络:用于输出状态 s 下每个动作的概率分布(使用 softmax)。
输入:state_dim -> 状态维度
hidden_dim -> 隐藏层维度
action_dim -> 动作维度
输出:softmax 归一化的动作概率
"""
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 第一层全连接
self.fc2 = torch.nn.Linear(hidden_dim, action_dim) # 第二层全连接
def forward(self, x):
x = F.relu(self.fc1(x)) # 使用 ReLU 激活函数
return F.softmax(self.fc2(x), dim=1) # 输出 softmax 动作概率分布
# 定义价值网络 ValueNet(用于估计状态价值)
class ValueNet(torch.nn.Module):
"""
价值网络:用于估计当前状态的价值(即状态的 V 值)。
输入:state_dim -> 状态维度
hidden_dim -> 隐藏层维度
输出:状态的 V 值
"""
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
# Actor-Critic 算法实现类
class ActorCritic:
"""
Actor-Critic 算法实现类,包含策略网络、价值网络、更新规则等。
"""
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
gamma, device):
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device) # 策略网络
self.critic = ValueNet(state_dim, hidden_dim).to(device) # 价值网络
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr) # 策略优化器
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),
lr=critic_lr) # 价值优化器
self.gamma = gamma # 折扣因子
self.device = device # 设备(CPU or GPU)
def take_action(self, state):
"""
根据当前状态选择动作(使用策略网络采样一个动作)。
参数:
state: 当前状态
返回:
action: 选择的动作编号
"""
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def update(self, transition_dict):
"""
使用经验数据更新 Actor 和 Critic 网络。
参数:
transition_dict: 包含 states, actions, rewards, next_states, dones 的字典
"""
# 将经验数据转换为 tensor 并移动到指定设备
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 计算时序差分目标 (TD Target)
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
# 计算 TD 误差(用于策略梯度更新)
td_delta = td_target - self.critic(states)
# 获取 log(prob) 并乘以 TD delta
log_probs = torch.log(self.actor(states).gather(1, actions))
actor_loss = torch.mean(-log_probs * td_delta.detach())
# 计算价值网络的均方误差损失
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
# 反向传播并更新参数
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward() # 更新策略网络
critic_loss.backward() # 更新价值网络
self.actor_optimizer.step()
self.critic_optimizer.step()
def train_on_policy_agent(env, agent, num_episodes):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}
state, _ = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, terminated, truncated, _ = env.step(action) # 执行动作
done = terminated or truncated # 合并两个条件作为 done 标志
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size - 1, 2)
begin = np.cumsum(a[:window_size - 1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
# 设置超参数
actor_lr = 1e-3 # 策略网络学习率
critic_lr = 1e-2 # 价值网络学习率
num_episodes = 1000 # 总共训练的回合数
hidden_dim = 128 # 网络隐藏层大小
gamma = 0.98 # 折扣因子
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# 创建环境
env_name = 'CartPole-v0'
env = gym.make(env_name) # 初始化环境
env.action_space.seed(0) # 设置动作空间种子
torch.manual_seed(0) # 设置 PyTorch 随机种子
# 获取状态空间和动作空间维度
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 实例化 Actor-Critic 算法对象
agent = ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
gamma, device)
# 记录每个 episode 的回报
return_list = []
# 开始训练
return_list = train_on_policy_agent(env, agent, num_episodes)
# 绘图展示训练过程中的回报曲线
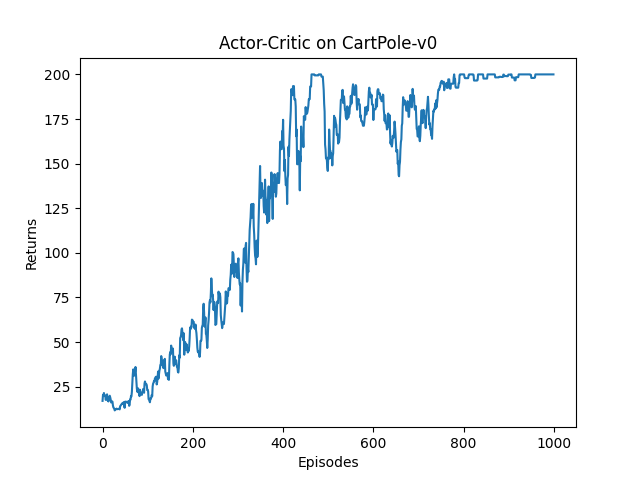
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Actor-Critic on {}'.format(env_name))
plt.show()
# 绘制滑动平均回报曲线
mv_return = moving_average(return_list, 9) # 9点滑动平均
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Actor-Critic on {}'.format(env_name))
plt.show()
五、PPO算法¶
学习目标:
1.理解PPO算法的PPO截断的含义
2.了解PPO算法的关键超参数
3.基于Stable-Baseline3测试PPO算法
5.1 为什么需要PPO¶
虽然 Actor-Critic 架构结合了策略梯度和价值评估的优点,但在实际训练中,它非常敏感且不稳定。
- 如果学习率(Step size)太大:策略更新步子迈得太大,可能导致策略发生剧烈变化。一旦策略变坏,采集到的数据就会变差,导致网络在错误的道路上越走越远,这种“崩塌”往往是不可逆的。
- 如果学习率太小:训练速度慢如蜗牛,很难收敛。
为了解决这个问题,我们要限制 Actor 每次更新的幅度。
理想情况下,我们希望每次更新策略时,新的策略 \(\pi_{new}\) 不要偏离旧策略 \(\pi_{old}\) 太远。我们要在一个“信任区域(Trust Region)”内安全地更新。
在PPO (Proximal Policy Optimization:近端策略优化)之前,有个算法叫 TRPO(信任区域策略优化),它用复杂的数学(KL散度约束 + 二阶优化)做到了这一点,但计算量极其巨大,很难工程化。
OpenAI 的研究人员想,能不能用一阶优化(像 SGD/Adam 这样简单的)就能实现 TRPO 的效果?于是,PPO 诞生了(2017年)。它通过简单的裁剪(Clipping)技巧,实现了既稳又快的训练。
一句话总结 PPO 的地位:它是 Actor-Critic 架构的“稳健升级版”,在保证策略不发生剧烈突变的前提下,尽可能大地提升性能。
5.2 PPO算法原理¶
PPO 的核心在于如何构造目标函数(Loss Function)。只要把这个 Loss 设计好,剩下的就是丢给 Adam 优化器去跑了。
PPO目标函数的设计,包含以下几个核心知识点:
- 优势函数
- 概率比
- 裁剪机制
- 广义优势估计
5.2.1 优势函数¶
公式3.3的策略梯度公式: $$ \theta_{t+1} = \theta_t + \alpha \nabla_\theta \ln \pi(a_t|s_t, \theta_t) q_t(s_t, a_t), \quad (3.3) $$ 其中使用的是 \(q_t(s_t, a_t)\)(动作价值),直接使用\(q_t(s_t, a_t)\),容易面临以下两个严重问题:
问题一:方差(Variance)太大,训练不稳定
假设环境的奖励设计是“只要活着每一步都给 +1000 分”。
- 动作 A 的 \(Q\) 值是 1000。
- 动作 B 的 \(Q\) 值是 1010。
- 在数学上,梯度会试图同时推高这两个动作的概率(因为 \(Q\) 都是巨大的正数),虽然 B 推得稍微猛一点点。但这会造成梯度的剧烈波动,因为数值太大了,就像在平地上开 F1 赛车,稍微一踩油门就飞出去了。
问题二:无法明确区分好坏
如果 \(Q\) 值恒为正,策略网络收到的信号永远是“这个动作好,增加概率!”。网络只能靠“增加幅度的微小差异”来慢慢区分好坏,效率极低。
目前, PPO、A3C、TRPO、GRPO 等现代算法中,这个 \(q_t\) 几乎都被 \(A_t\)(优势函数,Advantage Function) 替代了。
优势函数的定义公式:
\(A(s, a) = Q(s, a) - V(s)\)
- \(Q(s, a)\):在状态 \(s\) 下,采取特定动作 \(a\),然后遵循当前策略能得到的期望回报。
- \(V(s)\):在状态 \(s\) 下,平均来看(不限定动作,按照策略 \(\pi\) 随机选)能得到的期望回报。
直观理解(考试打分比喻): 想象你在参加一场考试,满分100分。
- \(Q(s, a)\)(绝对分数):你考了 80分。
- 但这算好还是坏呢?这取决于题目的难易程度(即状态 \(s\) 的好坏)。
- \(V(s)\)(平均基准):全班的平均分是 70分。
- \(A(s, a)\)(相对优势):你的分数减去平均分:\(80 - 70 = \mathbf{+10}\)。
结论:
- 如果 \(A > 0\):说明这个动作 \(a\) 比该状态下的平均表现要好,应该鼓励(增加概率)。
- 如果 \(A < 0\):说明这个动作 \(a\) 比该状态下的平均表现要差,应该抑制(减小概率)。
5.2.2 概率比¶
标准的策略梯度中,我们是用当前策略 \(\pi_\theta\) 收集数据并更新。一旦更新了参数,旧数据就扔掉了,这很浪费。 PPO 允许我们利用旧策略 \(\pi_{\theta_{old}}\) 采样的数据来更新新策略 \(\pi_\theta\)。这涉及到一个重要性采样的概念。
我们定义一个比率 \(r_t(\theta)\): $$ r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} $$
- 如果 \(r_t(\theta) > 1\),说明新策略比旧策略更倾向于在这个状态下采取这个动作。
- 如果 \(0 < r_t(\theta) < 1\),说明新策略采取这个动作的概率变小了。
- 初始时刻,新旧策略参数一样,所以 \(r_t(\theta) = 1\)。
5.2.3 裁剪机制¶
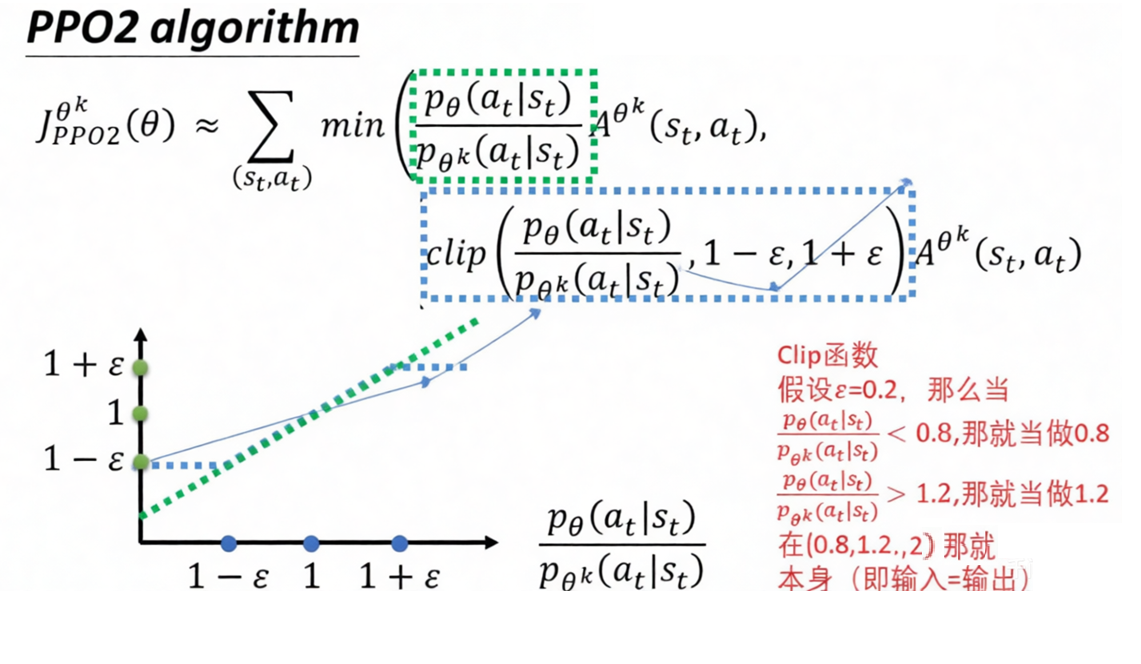
PPO的一个重要创新就是引入了裁剪机制,引入裁剪机制后的策略梯度部分的目标函数是
\(L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min( \underbrace{r_t(\theta) A_t}_{\text{原始目标}}, \underbrace{\text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t}_{\text{截断目标}} ) \right]\)
其中:
1、\(L^{CLIP}(\theta)\):策略梯度部分的目标函数
-
含义:这是我们需要最大化的目标函数(在代码中通常取负值作为 Loss 来最小化)。
-
\(\theta\) (Theta):策略网络(Actor)的参数(即神经网络的权重和偏置)。我们的目标就是通过调整 \(\theta\) 来让这个函数的值变大。
-
CLIP:表示该函数使用了“裁剪(Clipping)”机制。
2、\(\mathbb{E}_t [\dots]\):期望 (Expectation)
-
含义:表示对一个批次(Batch)的数据取平均值。
-
作用:在实际训练中,我们不会只看某一步的表现,而是把一轮采样下来的所有时间步 \(t\) 的数据计算一遍,然后取平均,作为整体的优化目标。
3、\(\min(\dots)\):取最小值
-
含义:在括号里的两项中选择较小的那一项。
-
作用(非常关键):这是一种悲观(Pessimistic)的策略。它确保我们得到的估计是保守的下界。
- 如果策略更新太激进(超出了限制范围),\(\min\) 函数会强制我们忽略超出部分的收益。这构成了 PPO 的“安全护栏”。
4、 \(r_t(\theta)\):概率比率 (Probability Ratio)
-
公式:\(r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\)
-
\(\pi_\theta(a_t|s_t)\):新策略(当前正在更新的策略)在状态 \(s_t\) 下采取动作 \(a_t\) 的概率。
-
\(\pi_{\theta_{old}}(a_t|s_t)\):旧策略(收集这批数据时的策略)在状态 \(s_t\) 下采取动作 \(a_t\) 的概率。
-
作用:衡量新旧策略的差异。
- 如果 \(r_t = 1\),说明新旧策略没变化。
- 如果 \(r_t > 1\),说明新策略比旧策略更倾向于选这个动作。
- 如果 \(r_t < 1\),说明新策略选这个动作的概率变小了。
5、\(A_t\):优势函数 (Advantage Function)
-
含义:评价动作 \(a_t\) 在状态 \(s_t\) 下到底有多好。
- \(A_t > 0\):动作 \(a_t\) 表现优于平均水平,应该增加其概率(鼓励)。
- \(A_t < 0\):动作 \(a_t\) 表现差于平均水平,应该减小其概率(抑制)。
-
来源:通常由 Critic 网络计算得出(如使用 GAE 算法)。
6、\(\text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\):裁剪函数
-
含义:将比率 \(r_t(\theta)\) 强行限制在 \([1-\epsilon, 1+\epsilon]\) 这个区间内。
- 如果 \(r_t > 1+\epsilon\),就强制变成 \(1+\epsilon\)。
- 如果 \(r_t < 1-\epsilon\),就强制变成 \(1-\epsilon\)。
-
作用:这就是“截断目标”的核心,防止概率比率变化过于剧烈。
7、\(\epsilon\) (Epsilon):超参数
-
含义:裁剪范围阈值。
-
常用值:通常设为 \(0.1\) 或 \(0.2\)。
-
作用:它定义了“信任区域”的大小。例如 \(\epsilon=0.2\),意味着我们只允许新策略的概率相对于旧策略在 \(80\% \sim 120\%\) 之间波动。
8、 两项内容的对比解释,公式中 \(\min\) 比较的是这两项:
-
\(r_t(\theta) A_t\)(原始目标):
-
这是最原始的策略梯度目标(TRPO 里的 surrogate objective)。
-
如果不加限制,当 \(A_t\) 很大时,网络会试图让 \(r_t\) 变得无穷大,导致策略更新步子太大而崩盘。
- \(\text{clip}(\dots) A_t\)(截断目标):
- 这是限制后的目标。它告诉网络:“即使你觉得这个动作再好,概率提升也不要超过 \(1+\epsilon\) 倍;即使再差,概率降低也不要超过 \(1-\epsilon\) 倍。”
总结:这个公式在做什么?
这个公式在对策略网络说:
“请调整你的参数 \(\theta\),让好的动作(\(A_t>0\))概率变大,坏的动作(\(A_t<0\))概率变小。 但是(But)! 如果你改得太猛了(超出了 \(1 \pm \epsilon\) 的范围),多出来的部分我就不算你的功劳(或者不惩罚你)了(梯度为0),这样能确保你每次只迈出一小步,稳稳地训练。”
5.2.4 广义优势估计(GAE)¶
在 PPO中,Critic 计算优势函数 \(A_t\) 的方法通常使用 GAE。 简单来说,GAE 是一种平衡方差(Variance)和偏差(Bias)的计算回报的方法。
- 它结合了多步 TD 误差。
- 通过调整参数 \(\lambda\)(Lambda),我们可以在“看一步”(TD)和“看到底”(Monte Carlo)之间找到最佳平衡点,让 Critic 的打分更准。
5.2.4.1 基础:TD Error (时序差分误差)¶
Critic 网络输出的是状态价值 \(V(s)\)。我们定义 \(t\) 时刻的 TD Error 为 \(\delta_t\): $$ \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) $$ 这个 \(\delta_t\) 其实就是“一步优势估计(1-step Advantage)”。它偏差大,但方差小。
5.2.4.2 进阶:多步回报与权衡¶
我们可以往后多看几步来估计回报:
- 1步优势: \(\hat{A}_t^{(1)} = \delta_t\)
- 2步优势: \(\hat{A}_t^{(2)} = \delta_t + \gamma \delta_{t+1}\)
- ...
- 无穷步优势 (Monte Carlo): \(\hat{A}_t^{(\infty)} = \sum_{k=0}^\infty \gamma^k \delta_{t+k}\)
Bias-Variance Trade-off (偏差-方差权衡):
- 只看1步 (\(\hat{A}_t^{(1)}\)):非常依赖 Critic 网络当前的估值 \(V(s_{t+1})\)。如果 Critic 还没训练好(Bias大),这个优势估计就是错的。
- 看无穷步 (\(\hat{A}_t^{(\infty)}\)):直接用真实回报减去基线。虽然真实回报无偏(Unbiased),但由于环境随机性,每条轨迹的波动巨大(High Variance),导致训练不稳定。
5.2.4.3 终极方案:GAE (Generalized Advantage Estimation)¶
GAE 巧妙地使用了指数加权平均,把上述所有步数的优势加权融合起来。引入一个新的超参数 \(\lambda\) (Lambda),范围 \([0, 1]\)。
GAE 的数学定义:
\(\hat{A}_t^{GAE} = (1-\lambda) (\hat{A}_t^{(1)} + \lambda \hat{A}_t^{(2)} + \lambda^2 \hat{A}_t^{(3)} + \dots)\)
经过数学推导(级数求和),它可以简化为非常优雅的形式:
\(\hat{A}_t^{GAE} = \sum_{l=0}^\infty (\gamma \lambda)^l \delta_{t+l}\)
代码实现时的递推公式(Recurrent Formula): 在实际代码中,我们是从后往前计算 GAE 的(Backwards):
\(\hat{A}_t^{GAE} = \delta_t + (\gamma \lambda) \hat{A}_{t+1}^{GAE}\) 其中 。
\(\lambda\) 的作用:
- \(\lambda = 0\):GAE 变为 \(r_t + \gamma V(s_{t+1}) - V(s_t)\)。即 TD(0)。低方差,高偏差。
- \(\lambda = 1\):GAE 变为 Monte Carlo 估计。高方差,低偏差。
- 通常取值:\(\lambda = 0.95\),在两者之间取得最佳平衡。
举例计算GAE:
GAE是“从后往前”计算,我们不是一边玩游戏一边算优势,而是先把游戏玩完(或者玩一段),存下所有数据,然后“倒着”算。
第一步:收集数据(假设我们让 Agent 在环境里跑了 3步(\(T=3\)),然后游戏结束了。我们在内存里存下了这 3 步的所有数据)
-
\(t=1\): \(r_1, V(s_1), V(s_2)\) → 算出 \(\delta_1\)
-
\(t=2\): \(r_2, V(s_2), V(s_3)\) → 算出 \(\delta_2\)
-
\(t=3\): \(r_3, V(s_3), V(s_{end})\) → 算出 \(\delta_3\)
\(\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\)
第二步:倒着计算 GAE(Backwards)
有了所有的 \(\delta\),我们现在开始从最后一步 \(t=3\) 往回推到 \(t=1\)。
我们设衰减因子 \(\gamma\lambda = 0.9\)。
1. 计算最后一步 (\(t=3\)): 公式:\(\hat{A}_3 = \delta_3 + 0.9 \cdot \hat{A}_4\)
- 因为游戏在第3步结束了,第4步不存在,所以 \(\hat{A}_4 = 0\)(这是递归的边界条件/Base Case)。
- 结果:\(\hat{A}_3 = \delta_3\)
2. 计算倒数第二步 (\(t=2\)): 公式:\(\hat{A}_2 = \delta_2 + 0.9 \cdot \hat{A}_3\)
- \(\hat{A}_3\) 我们刚才在第1步已经算出来了!直接代入即可。
- 结果:\(\hat{A}_2 = \delta_2 + 0.9 \cdot \delta_3\)
3. 计算第一步 (\(t=1\)): 公式:\(\hat{A}_1 = \delta_1 + 0.9 \cdot \hat{A}_2\)
- \(\hat{A}_2\) 我们刚才在第2步算出来了!直接代入。
- 结果:\(\hat{A}_1\) 也就求出来了。
5.2.5 损失函数¶
PPO算法中, 除了5.2.3小节中的策略梯度损失函数, 还包含价值损失(Value Loss)和熵损失(Entropy Loss)。
在实际代码(如 PyTorch/TensorFlow)中,我们通常是将这三者加权求和,计算一个总的 Loss 来进行反向传播。
5.2.5.1 价值损失¶
这是Critic 网络(评论家)需要优化的目标。
\(L^{VF}_t(\theta) = \left( V_\theta(s_t) - V_t^{\text{target}} \right)^2\)
(注:这是最基础的均方误差 MSE 形式,PPO 原文中其实也对这一项做了类似的 clip 操作,但本质都是为了让预测更准)
-
含义:
- \(V_\theta(s_t)\):Critic 网络预测在状态 \(s_t\) 下还能拿多少分。
- \(V_t^{\text{target}}\):实际训练中真实计算出来的回报(通常由奖励 \(r\) 和下一时刻价值估算得出)。
-
作用:让评委(Critic)打分更准。
- PPO 的策略更新极其依赖优势函数 \(A_t\)。
- 而 \(A_t\) 是基于 Critic 的打分计算的(\(A_t \approx r_t + \gamma V(s_{t+1}) - V(s_t)\))。
- 只有 Critic 准了,\(A_t\) 才准,Actor 才能知道往哪个方向改进。
5.2.5.2 熵损失 (Entropy Loss, \(S\))¶
这是一个附加项,用来鼓励探索(Exploration)。(即信息论中的熵,衡量分布的混乱程度)
\(S[\pi_\theta](s_t) = - \sum \pi_\theta(a|s_t) \log \pi_\theta(a|s_t)\)
-
含义:
- 高熵:策略很“纠结”,每个动作的概率差不多(例如 左:50%, 右:50%)。这代表随机性大,探索多。
- 低熵:策略很“确信”,某个动作概率接近 1(例如 左:99%, 右:1%)。这代表确定性高,探索少。
-
作用:防止过早收敛(Premature Convergence)。
- 在训练初期,我们希望 Agent 多尝试不同的动作(即保持高熵)。
- 如果不用这一项,Agent 可能刚尝到一点甜头,就死盯着一个动作不放(变得由于固执而局部最优)。
- 我们在目标函数中加上熵(或在 Loss 中减去熵),就是强行奖励“保持多样性”的行为。
5.2.5.3 PPO 完整总损失函数¶
PPO 一边想办法让策略收益最大化(且不步子太大),一边逼着Critic 估分更准(Value Loss),同时还顺带提醒 Agent 不要太固执,多尝试新东西(Entropy Loss)。
在代码实现中,我们要最小化的总 Loss 通常写成这样:
\(L^{Total} = \underbrace{- L^{CLIP}(\theta)}_{\text{策略损失 (最大化变为最小化)}} + \underbrace{c_1 L^{VF}(\theta)}_{\text{价值损失 (让打分更准)}} - \underbrace{c_2 S[\pi_\theta]}_{\text{熵损失 (鼓励探索)}}\)
- \(L^{CLIP}\) 前的负号:因为 \(L^{CLIP}\) 原本是收益,要最大化;而在深度学习框架里我们通常计算 Minimize Loss,所以加负号。
- \(c_1, c_2\):超参数系数。通常价值损失系数 \(c_1=0.5\),熵系数 \(c_2=0.01\)(熵的权重通常很小,作为辅助)。
5.3 PPO 算法流程¶
- 收集数据:用当前的 Actor \(\pi_{\theta_{old}}\) 在环境里跑 \(T\) 步,存下 \((s_t, a_t, r_t, s_{t+1}, \log\pi_{old})\).
- 计算 GAE:
- 先算每一步的 TD Error: \(\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\).
- 倒序计算优势: \(\hat{A}_t = \delta_t + (\gamma\lambda)\hat{A}_{t+1}\).
- 数据打包:把 \(T\) 步的数据作为一个 Batch。
- 多轮更新 (Epochs):
- 把 Batch 打乱,分成小批次 (Mini-batches)。
- 对于每个 Mini-batch:
- 计算新旧策略比率 \(r_t(\theta)\)。
- 计算 \(L^{CLIP}\)。
- 计算 \(L^{VF}\) (Critic MSE)。
- 计算熵 \(S\)。
- 反向传播,同时更新 Actor (\(\theta\)) 和 Critic (\(\phi\)) 的参数。
- 循环:更新完参数后,\(\theta_{new}\) 变 \(\theta_{old}\),回到第一步。
关键超参数
- 剪切范围
ε:通常设为0.1~0.3 - 学习率:策略网络和值网络可分开设置
- 折扣因子
γ:用于计算累积回报,通常取0.99 - GAE参数
λ:用于平衡优势估计的偏差和方差,通常取0.95~0.99
5.4 基于SB3实现PPO¶
# -*- coding: utf-8 -*-
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import BaseCallback
from stable_baselines3.common.env_util import make_vec_env
# 自定义回调函数:记录每个episode的回报
class RewardLogger(BaseCallback):
def __init__(self, verbose=0):
super(RewardLogger, self).__init__(verbose)
self.episode_rewards = [] # 存储所有episode的累计奖励
self.current_episode_reward = 0 # 当前episode的累计奖励
def _on_step(self) -> bool:
reward = self.locals['rewards'][0] # 获取当前步骤的奖励
self.current_episode_reward += reward
# 若episode结束,记录并重置累计奖励
if self.locals['dones'][0]:
self.episode_rewards.append(self.current_episode_reward)
self.current_episode_reward = 0
return True
# 创建环境
env = gym.make('CartPole-v0') # 使用 CartPole-v0 环境
# 初始化PPO模型
model = PPO(
policy='MlpPolicy',
env=env,
learning_rate=3e-4, # PPO常用的学习率
n_steps=2048, # 每次更新前的步数
batch_size=64, # 每个梯度下降的batch大小
ent_coef=0.01, # 熵系数,用于鼓励探索
clip_range=0.2, # PPO中的clip参数
n_epochs=10, # 每个batch重复训练的epoch数
gamma=0.99, # 折扣因子
gae_lambda=0.95, # GAE参数
verbose=1, # 打印训练日志
tensorboard_log="./ppo_logs" # TensorBoard日志目录
)
# 初始化回调函数
reward_logger = RewardLogger()
# 开始训练模型,设置总步数为 20000 步
model.learn(total_timesteps=20000, callback=reward_logger)
# 绘制回报曲线
plt.figure(figsize=(12, 6))
plt.plot(reward_logger.episode_rewards, alpha=0.6, label='Episode Reward')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('PPO Training Performance on CartPole-v0')
plt.grid(True)
# 添加10-episode移动平均线(平滑波动)
window_size = 10
moving_avg = np.convolve(
reward_logger.episode_rewards,
np.ones(window_size) / window_size,
mode='valid'
)
plt.plot(
range(window_size - 1, len(reward_logger.episode_rewards)),
moving_avg,
'r-',
linewidth=2,
label=f'{window_size}-Episode Moving Avg'
)
plt.legend()
plt.tight_layout()
plt.show()
5.5 On-Policy与Off-Policy¶
5.5.1 On-Policy路线¶
- 核心思想:直接使用当前策略(Policy)与环境(或人类)交互产生的数据来更新模型。
-
代表性算法:PPO算法
-
技术特点:
- 数据来源:当前策略实时生成的新数据(如模型最新生成的回答)。
- 策略更新:数据采集 → 立即用于训练 → 策略更新 → 循环迭代。
- 优势:策略更新及时,适应动态反馈;适合高交互场景。
- 劣势:数据效率低(需大量人类实时反馈);训练不稳定(策略突变风险)
5.5.2 Off-Policy 路线¶
- 核心思想:利用其他策略(如旧策略或人类演示)生成的数据来训练当前策略。
- 代表性算法:DQN算法、SAC算法、Q-Learning算法
-
技术特点:
- 数据来源:历史数据池(如人类演示、旧策略生成的回答)
- 策略更新:从固定数据集中采样训练,与当前策略的实时表现无关。
- 优势:数据效率高(可复用历史数据);训练稳定(避免策略突变)
- 劣势:反馈滞后,难以适应新需求;依赖高质量历史数据
六、GRPO算法¶
学习目标:
1.理解PPO算法在大模型训练与微调任务中的痛点
2.理解GRPO算法的核心思想
3.知道GRPO算法的实现流程
4.知道GRPO算法与PPO算法的不同
6.1 PPO 在大模型时代的痛点¶
前边我们学过的 PPO(近端策略优化)是目前强化学习领域的“标配”,它通过 Actor-Critic 架构,利用价值网络(Critic)来计算优势函数 \(A_t\),从而稳定地更新策略。
但是,随着大语言模型(LLM)时代的到来,特别是像 DeepSeek-R1、DeepSeek-Math 这样需要进行复杂推理的模型出现后,研究人员发现 PPO 在某些方面变得“不够用了”,或者说“太贵了”。
于是,一种专门为 LLM 强化学习设计的算法应运而生——GRPO(Group Relative Policy Optimization,群体相对策略优化)。
让我们回顾一下 PPO 的标准架构:Actor-Critic。
- Actor (策略模型):负责生成文本(参数量巨大,比如 70B)。
- Critic (价值模型):负责给文本打分,预测 \(V(s)\)(通常也需要一个同样巨大的模型,也是 70B)。
痛点 1:显存开销太大(Memory Wall) 在训练 LLM 时,一个 70B 的模型已经占满了显卡。如果用 PPO,你还需要加载一个同样大小的 Critic 模型,显存直接爆炸。虽然可以共享部分参数,但优化起来非常复杂。
痛点 2:价值评估困难 在数学题或代码生成任务中,奖励通常是二元的(做对了给1分,做错了给0分)。
- Critic 很难精准预测这种稀疏奖励的价值 \(V(s)\)。
- 如果 Critic 算不准,优势函数 \(A_t\) 就由于偏差(Bias)算不准,PPO 的效果就会大打折扣。
思考:有没有一种方法,不需要 Critic 模型,也能算出优势函数 \(A_t\) 呢? 答案就是 GRPO。
6.2 GRPO 的核心直觉——“全靠同行衬托”¶
GRPO 抛弃了 Critic 网络。那么它如何判断一个动作的好坏呢? 它采用了一种“组内竞争(Group Competition)”的机制。
直观例子:考试排名
- PPO (Critic 模式):小明考了 80 分。Critic(老师)预测平均分应该是 75 分。优势 = 80 - 75 = +5 分。你需要一个经验丰富的老师(Critic)来预测平均分。
- GRPO (Group 模式):小明考了 80 分。我不知道平均分是多少,但我让全班同学都做同一套题。 小红:60分 小刚:90分 小明:80分 组内比较:算出这组分数的平均值是 76.6,标准差是 12.5。 小明的相对优势 = \((80 - 76.6) / 12.5\)。
核心思想: 不需要训练一个 Critic 来预测基线(Baseline),我们直接针对同一个问题(Prompt),采样一组不同的回答(Outputs),用这组回答的平均奖励作为基线。
6.3 GRPO 算法流程详解¶
GRPO 的流程非常简洁,主要分为三步:采样(Sampling)、评估(Evaluation)、更新(Optimization)。
6.3.1 采样 (Group Sampling)¶
对于每一个输入问题(Prompt)\(q\),我们让旧策略 \(\pi_{\theta_{old}}\) 生成 \(G\) 个 不同的输出结果 \(\{o_1, o_2, \dots, o_G\}\)。
- 这里的 \(G\) 是组的大小(Group Size),比如 \(G=64\)。
- 这就构成了一组数据:\(\{ (q, o_i) \}_{i=1}^G\)。
6.3.2 评估与优势计算 (Advantage Estimation)¶
我们有一个奖励模型(Reward Model)或者规则检查器(Rule Checker,比如数学题答案校验),给这 \(G\) 个输出打分,得到奖励 \(\{r_1, r_2, \dots, r_G\}\)。
关键点:如何计算优势 \(A_i\)? GRPO 使用组内的标准化奖励作为优势:
- \(\text{mean}(r)\):这组奖励的平均值。这其实就是基线(Baseline)。
- \(\text{std}(r)\):这组奖励的标准差。
- 含义:如果 \(A_i > 0\),说明第 \(i\) 个回答比这组生成的其他回答要好,应该鼓励;反之则抑制。
注意: 这里完全不需要 Critic 网络参与!我们直接用统计学方法消除了状态价值的影响。
6.3.3 目标函数 (The Objective)¶
GRPO 的损失函数由两部分组成:PPO 风格的策略损失 + KL 散度惩罚。
策略损失 (Policy Loss)
这部分和 PPO 几乎一模一样,使用了 Clip 机制: $$ J_{GRPO}(\theta) = \frac{1}{G} \sum_{i=1}^G \left[ \min \left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i, \quad \text{clip}(\dots) A_i \right) \right] $$
- 我们对组内的 \(G\) 个样本取平均。
- 利用计算出的相对优势 \(A_i\) 来更新策略。
KL 散度惩罚 (KL Penalty)
为了防止模型为了刷高分而“胡言乱语”(比如输出不可读的文本但包含正确答案),或者偏离原始模型太远,我们需要加一个正则项。 我们需要一个参考模型(Reference Model) \(\pi_{ref}\)(通常是训练前的 SFT 模型)。
我们希望当前的策略 \(\pi_\theta\) 不要偏离 \(\pi_{ref}\) 太多: $$ D_{KL}(\pi_\theta || \pi_{ref}) = \frac{\pi_\theta(o_i|q)}{\pi_{ref}(o_i|q)} - \log \frac{\pi_\theta(o_i|q)}{\pi_{ref}(o_i|q)} - 1 $$ (注:这里通常使用一种近似计算方式)
总目标
$$ \text{Loss} = - J_{GRPO} + \beta \cdot D_{KL} $$ 我们最小化这个 Loss。
6.4 GRPO vs PPO 核心对比总结¶
| 特性 | PPO (Actor-Critic) | GRPO (Group Relative) |
|---|---|---|
| 模型结构 | 需要 Actor 和 Critic 两个大模型 | 只需要 Actor (加一个冻结的 Reference Model) |
| 优势计算 (\(A_t\)) | \(A_t = r + \gamma V_{next} - V_{curr}\) (依赖 Critic) | \(A_i = (r_i - \text{Avg}) / \text{Std}\) (依赖组内统计) |
| 计算资源 | 极高 (显存占用大) | 较低 (省去 Critic 的显存) |
| 适用场景 | 通用 (连续控制、游戏、NLP) | LLM 推理 (数学、代码、逻辑) |
6.5 为什么 GRPO 在 DeepSeek-R1 中成功了?¶
GRPO 之所以能在 DeepSeek-R1(以及 DeepSeek-Math)中大放异彩,主要有以下原因:
- 省钱省力:去掉了 Critic,训练成本大幅下降,使得在超大规模参数(如 70B+)上进行强化学习成为可能。
- 适合推理任务:
- 对于写诗、聊天,结果好坏很主观,需要 Reward Model (Critic) 细致打分。
- 但对于数学/代码,结果是对是错很明确(Answer is correct/incorrect)。GRPO 通过生成一组答案,大概率里面会有对有错,直接比较“对的比错的好多少”,信号非常强烈且有效。
- 鼓励探索:采样一组数据(Group Sampling)本身就是一种探索。模型被鼓励去生成多种可能得解题路径,只要最后答案对,且路径清晰,就能在组内脱颖而出。
七、强化学习实战-月球登陆器控制任务(扩展)¶
学习目标:
1.知道项目背景与数据情况
2.完成项目开发
6.1 安装库¶
pip install swig
pip install "gymnasium[box2d]"
6.2 任务背景¶
月球登陆器的精准控制任务是人类深空探测的关键挑战,其核心目标是在极端环境下实现安全、精确的软着陆。任务旨在未知环境中实现精度控制,控制登月舱在指定区域平稳着陆,需平衡燃料消耗、着陆速度和姿态角度。
6.3 实现流程¶
- 1.环境准备与配置
- 使用 gymnasium.make("LunarLander-v3") 创建标准 LunarLander 环境
- 2.模型构建与初始化
- 使用 Stable Baselines3 中的 PPO 算法
- 定义策略网络结构(两层隐藏层(每层 128 个神经元))
- 设置超参数:折扣因子、经验缓冲区大小、批量大小、熵系数等
- 3.训练过程设置
- 使用 model.learn() 启动训练过程
- 设置总训练步数(默认为 200,000 步)
- 注册回调函数:
- EvalCallback:定期评估并保存最佳模型
- EpisodeRewardLogger:记录每个 episode 的回报值
- 4.模型保存与加载
- 使用 model.save() 保存训练完成后的模型
- 使用 PPO.load() 加载已训练好的模型
- 5.模型评估与性能分析
- 使用 evaluate_policy() 对模型进行多轮评估(默认 10 轮)
- 输出平均奖励及标准差,用于衡量模型表现
- 6.模型测试与渲染展示
- 使用gym.make("LunarLander-v3", render_mode="human")创建带渲染的独立环境
- 使用 model.predict() 控制智能体执行动作
- 判断 terminated 或 truncated 来重置环境
- 7.训练结果可视化
- 使用 matplotlib 绘制每个 episode 的回报曲线
- 添加移动平均线平滑波动,便于观察趋势
6.4 代码实现¶
# -*- coding: utf-8 -*-
import gymnasium as gym # Gymnasium 环境库
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import SubprocVecEnv, VecMonitor
from stable_baselines3.common.env_util import make_vec_env
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.callbacks import EvalCallback, BaseCallback
import matplotlib.pyplot as plt
import numpy as np
if __name__ == '__main__':
"""
主程序入口:创建环境、训练模型、测试模型并可视化训练过程
"""
# 创建单个 LunarLander-v3 环境
env = gym.make('LunarLander-v3') # 使用 LunarLander-v3 环境(v2 已弃用)
# 定义策略网络结构(两层隐藏层,每层128个神经元)
policy_kwargs = dict(
net_arch=[128, 128] # 两层隐藏层,每层128个神经元
)
# 初始化 PPO 模型
model = PPO(
"MlpPolicy", # 使用多层感知机策略(适用于低维状态空间)
env, # 绑定 Gymnasium 环境
policy_kwargs=policy_kwargs,
gamma=0.99, # 折扣因子 γ,控制未来奖励的重要性
n_steps=2048, # 每次更新前的步数(经验缓冲区大小)
batch_size=64, # 每次优化使用的批量大小
ent_coef=0.01, # 熵系数(鼓励探索)
verbose=1, # 打印训练信息
tensorboard_log="./lunar_log/" # TensorBoard 日志路径
)
# 添加评估回调函数(可选):定期评估模型性能并保存最佳模型
eval_callback = EvalCallback(
env,
eval_freq=10_000, # 每1万步评估一次
best_model_save_path="./best_model/", # 最佳模型保存路径
deterministic=True, # 使用确定性策略进行评估
render=False # 评估时不渲染画面
)
# 自定义回调类:记录每个 episode 的回报值
class EpisodeRewardLogger(BaseCallback):
def __init__(self, verbose=0):
super(EpisodeRewardLogger, self).__init__(verbose)
self.episode_rewards = [] # 存储每个 episode 的总奖励
def _on_step(self) -> bool:
"""
每一步都会调用此方法,检查当前是否为一个完整的 episode 结束
如果是,则将 episode 的总奖励添加到列表中
"""
if 'episode' in self.locals.get('infos', [{}])[0]:
info = self.locals['infos'][0]
self.episode_rewards.append(info['episode']['r']) # 记录 episode 奖励
return True # 返回 True 表示继续训练
reward_logger = EpisodeRewardLogger()
# 开始训练模型(总共训练 200,000 步)
model.learn(
total_timesteps=200_000, # 总共训练的步数
callback=[eval_callback, reward_logger], # 注册回调函数
tb_log_name="PPO" # TensorBoard 日志名称
)
# 保存训练完成后的最终模型
model.save("ppo_lunarlander")
# 加载已保存的模型
model = PPO.load("ppo_lunarlander")
# 评估模型性能(默认使用 10 个 episode)
mean_reward, std_reward = evaluate_policy(model, env, n_eval_episodes=10)
print(f"Mean reward: {mean_reward:.2f} ± {std_reward:.2f}")
# 测试模型并渲染
# 创建一个用于渲染的独立环境(非向量化)
render_env = gym.make("LunarLander-v3", render_mode="human")
# 重置环境
obs, _ = render_env.reset()
for _ in range(1000): # 运行最多1000步
action, _states = model.predict(obs, deterministic=True) # 使用模型预测动作
obs, reward, terminated, truncated, info = render_env.step(action) # 执行动作
if terminated or truncated: # 判断 episode 是否结束
obs, _ = render_env.reset() # 重置环境
# 关闭渲染窗口
render_env.close()
# 可视化训练过程中每个 episode 的回报曲线
plt.figure(figsize=(12, 6))
plt.plot(reward_logger.episode_rewards, alpha=0.6, label='Episode Reward')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('PPO Training Performance on LunarLander-v3')
plt.grid(True)
# 添加移动平均线(平滑波动)
window_size = 10
moving_avg = np.convolve(reward_logger.episode_rewards,
np.ones(window_size) / window_size,
mode='valid')
plt.plot(
range(window_size - 1, len(reward_logger.episode_rewards)),
moving_avg,
'r-', linewidth=2,
label=f'{window_size}-Episode Moving Avg'
)
plt.legend()
plt.tight_layout()
plt.savefig("ppo_lunarlander_rewards.png", dpi=300)
plt.show()
作业¶
1.安装Stable-Baselines3库
2.说明DQN算法的特点
3.说明策略梯度算法的特点
4.说明Actor-Critic架构
5.推导并理解PPO算法的损失函数
6.推导并理解GRPO算法的损失函数
7.动手实现基于Stable-Baselines3实现DQN
8.动手实现基于Stable-Baselines3实现PPO