强化学习基础算法¶
一、蒙特卡洛方法¶
学习目标:
1.理解什么是蒙特卡洛方法
2.动手实现蒙特卡洛方法估计状态价值
1.1 什么是蒙特卡洛方法¶
想象你置身于摩纳哥的蒙特卡洛赌场,轮盘转动、骰子翻滚,每一局结果充满随机性。而20世纪40年代,美国“曼哈顿计划”的科学家乌拉姆(S.M. Ulam)和冯·诺伊曼(John von Neumann)却从赌城的随机游戏中获得灵感,开创了一种用随机数解决确定性难题的计算方法——蒙特卡洛方法(Monte Carlo Method)

蒙特卡洛方法(Monte Carlo method)也被称为统计模拟方法,是一种基于概率统计的数值计算方法。运用蒙特卡洛方法时,我们通常使用重复随机抽样,然后运用概率统计方法来从抽样结果中归纳出我们想得到的目标的数值估计。
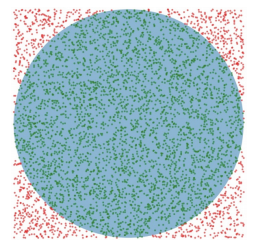
一个简单的例子是用蒙特卡洛方法来估计圆的面积,如下图所示的正方形内部随机产生若干个点,细数落在圆中的点的个数,圆的面积与正方形的面积之比就等于圆中点的个数与正方形中点的个数之比。随机产生的点的个数越多,计算得到圆的面积就越接近于真实的圆的面积。
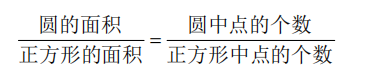
1.2 蒙特卡洛方法估计状态价值¶
现在我们准备用蒙特卡洛方法来估计一个策略在一个马尔可夫决策过程中的状态价值。
一个状态的价值是它的期望回报,那么一个很直观的想法就是用策略在 MDP 上采样很多条序列,计算从这个状态出发的回报再求其期望就可以了,公式如下:
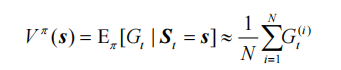
假设我们现在用策略pi 从状态 s 开始采样序列,据此来计算状态价值。我们为每一个状态维护一个计数器和总回报,计算状态价值的具体过程如下所示。
- 第一步:使用策略\(\pi\)采样若干条序列:
\(s_0 \stackrel{a_0^{(0)}}{\rightarrow} r_0^{(0)} \stackrel{}{\rightarrow} s_1 \stackrel{a_1^{(1)}}{\rightarrow} r_1^{(1)} \stackrel{}{\rightarrow} s_2 \stackrel{a_2^{(2)}}{\rightarrow} \cdots \stackrel{}{\rightarrow} r_{T-1}^{(T-1)} \stackrel{}{\rightarrow} s_T\)
-
第二步:对每一条序列中的每一时间步t 的状态 s 进行以下操作:
- 更新状态 s 的计数器\(N(s) \leftarrow N(s) + 1\)
- 更新状态 s 的总回报\(M(s) \leftarrow M(s) + G\)
-
每一个状态的价值被估计为回报的期望\(V(s) = M(s) / N(s)\)
根据大数定律,当\(N(s) \rightarrow \infty\)时,有\(V(s) \rightarrow V^\pi(s)\)。计算回报的期望时,除了可以把所有的回报加起来除以次数,还有一种增量更新的方法。对于每个状态 s 和对应回报G ,进行如下计算:
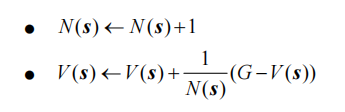
这种增量更新的方法可以大幅降低计算复杂度,推导同MAB中估计期望奖励时的方法。
- 代码实现
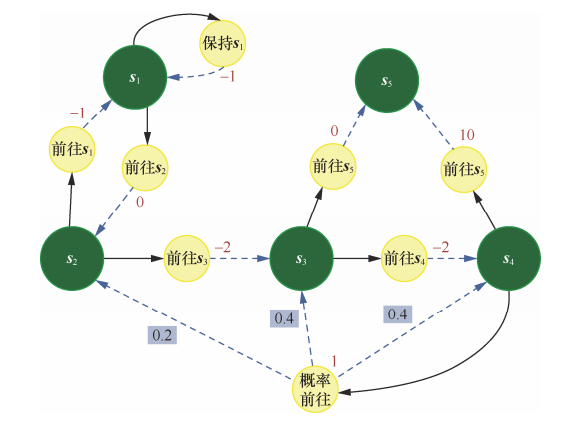
上图中,其中每个深色圆圈代表一个状态,一共有 s1~s5 这 5 个状态。
黑色实线箭头代表可以采取的动作,浅色小圆圈代表动作每个浅色小圆圈旁的数字代表在某个状态下采取某个动作能获得的奖励。虚线箭头代表采取动作后可能转移到的状态,箭头边上的数字代表转移概率,如果没有数字则表示转移概率为1。
例如:在 s2下,如果采取动作“前往 s3”,就能得到奖励−2,并且转移到 s3;在 s4下,如果采取“概率前往”,就能得到奖励 1,并且会分别以概率 0.2、0.4、0.4 转移到 s2、s3或 s4。
- 代码实现
-
接下来我们首先用代码定义上图的MDP
# -*- coding: utf-8 -*- import numpy as np S = ["s1", "s2", "s3", "s4", "s5"] # 状态集合 A = ["保持 s1", "前往 s1", "前往 s2", "前往 s3", "前往 s4", "前往 s5", "概率前往"] # 动作集合 # 状态转移函数 P = { "s1-保持 s1-s1": 1.0, "s1-前往 s2-s2": 1.0, "s2-前往 s1-s1": 1.0, "s2-前往 s3-s3": 1.0, "s3-前往 s4-s4": 1.0, "s3-前往 s5-s5": 1.0, "s4-前往 s5-s5": 1.0, "s4-概率前往-s2": 0.2, "s4-概率前往-s3": 0.4, "s4-概率前往-s4": 0.4, } # 奖励函数 R = { "s1-保持 s1": -1, "s1-前往 s2": 0, "s2-前往 s1": -1, "s2-前往 s3": -2, "s3-前往 s4": -2, "s3-前往 s5": 0, "s4-前往 s5": 10, "s4-概率前往": 1, } # 策略 1,随机策略 Pi_1 = { "s1-保持 s1": 0.5, "s1-前往 s2": 0.5, "s2-前往 s1": 0.5, "s2-前往 s3": 0.5, "s3-前往 s4": 0.5, "s3-前往 s5": 0.5, "s4-前往 s5": 0.5, "s4-概率前往": 0.5, } gamma = 0.5 # 折扣因子 MDP = (S, A, P, R, gamma) -
然后用代码定义一个采样函数。采样函数需要遵守状态转移矩阵和相应的策略,每次将(s,a,r,s_next)元组放入序列中,直到到达终止序列。然后我们通过该函数,用随机策略在上图 的 MDP 中实际采样几条序列。
# 把输入的两个字符串通过 "-" 连接,便于使用上述定义的 P、R 变量 def join(str1, str2): return str1 + '-' + str2 def sample(MDP, Pi, timestep_max, number): """ 序列采样方法 @param MDP: MDP过程 @param Pi: 策略 @param timestep_max: 序列上限 @param number: 采样多少条序列 @return: 序列采样结果 """ episodes = [] S, A, P, R, gamma = MDP for _ in range(number): episode = [] # 列表存储序列 timestep = 0 s = S[np.random.randint(4)] # 随机选除 s5 外状态 while s != "s5" and timestep <= timestep_max: timestep += 1 # 均匀分布的随机数 rand, temp = np.random.rand(), 0 # 根据策略选动作 """ 轮盘赌选取法 作用:精准匹配 “概率权重” 与 “随机选择” 的对应关系,让每个选项被选中的概率严格等于其预设权重, 既保证随机性,又不偏离概率分布 两个变量:rand: [0,1] 区间,均匀分布的随机数,代表 "指针位置" temp: 累积概率,初始化为 0, 在遍历动作的时候,不断累加每个动作的概率 工作原理: 1.将策略 P 给出的每个动作的概率,视为轮盘上的一个扇形区域,面积与概率成正比, 2.通过累加 temp, 相当于构建累积概率分布 例如:三个动作的概率分别是 0.2, 0.5, 0.3, 累积概率就是:0.2, 0.7, 1.0 3.当累积概率 temp 首次超过 rand 时,意味着 rand 落在当前动作对应的概率区间了, 因此就选择该动作 """ for a_opt in A: temp += Pi.get(join(s, a_opt), 0) if temp > rand: a = a_opt r = R.get(join(s, a), 0) break rand, temp = np.random.rand(), 0 # 根据转移概率选下一状态 for s_opt in S: temp += P.get(join(join(s, a), s_opt), 0) if temp > rand: s_next = s_opt break episode.append((s, a, r, s_next)) s = s_next episodes.append(episode) return episodes # 采样 5 次,每个序列最长不超过 20 步 episodes = sample(MDP, Pi_1, 20, 5) print('第一条序列\n', episodes[0]) print('第二条序列\n', episodes[1]) print('第五条序列\n', episodes[4]) -
最后使用蒙特卡洛方法对所有采样序列计算所有状态的价值
# 对所有采样序列计算所有状态的价值 def MC(episodes, V, N, gamma): for episode in episodes: G = 0 for i in range(len(episode) - 1, -1, -1): # 一个序列从后往前计算 (s, a, r, s_next) = episode[i] G = r + gamma * G N[s] = N[s] + 1 V[s] = V[s] + (G - V[s]) / N[s] timestep_max = 20 # 采样 1000 次,可以自行修改 episodes = sample(MDP, Pi_1, timestep_max, 1000) gamma = 0.5 V = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0} N = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0} MC(episodes, V, N, gamma) print("使用蒙特卡洛方法计算 MDP 的状态价值为\n", V)
二、动态规划算法¶
学习目标:
1.了解基于动态规划的强化学习算法
2.1 基于动态规划的强化学习算法¶
动态规划(dynamic programming)是程序设计算法中非常重要的内容,能够高效地解决一些经典问题,例如背包问题和最短路径规划。动态规划的基本思想是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到目标问题的解。动态规划会保存已解决的子问题的答案,在求解目标问题的过程中,需要这些子问题的答案时就可以直接利用,避免重复计算。
基于动态规划的强化学习算法主要有两种:
- 一是策略迭代(policy iteration),策略迭代由两部分组成:策略评估(policy evaluation)和策略提升(policy improvement),策略迭代中的策略评估使用贝尔曼期望方程来得到一个策略的状态价值函数,这是一个动态规划的过程。
- 二是价值迭代(value iteration),价值迭代直接使用贝尔曼最优方程来进行动态规划,得到最终的最优状态价值函数。
基于动态规划的强化学习算法主要特点:
- 动态规划是有模型算法,要求事先知道环境的状态转移函数和奖励函数,也就是需要知道整个马尔可夫决策过程。在这样一个白盒环境中,不需要通过智能体和环境的大量交互来学习,可以直接用动态规划求解状态价值函数。
- 策略迭代和价值迭代通常只适用于有限马可夫决策过程,即状态空间和动作空间是离散且有限的。
所以动态规划算法有其局限之处,我们无法将其运用到很多实际场景中。
三、时序差分算法(TD)¶
学习目标:
1.理解时序差分相关基础概念
2.了解Sarsa算法基本原理
4.了解Q-learning算法基本原理
5.理解在线策略与离线策略
3.1 时序差分介绍¶
3.1.1 无模型强化学习¶
前边介绍的动态规划算法要求马尔可夫决策过程是已知的,即要求与智能体交互的环境是完全已知的(例如迷宫或者给定规则的网格世界)。在此条件下,智能体其实并不需要和环境真正交互来采样数据,直接用动态规划算法就可以解出最优价值或策略。
但这在大部分场景下并不现实,机器学习的主要方法都是在数据分布未知的情况下针对具体的数据点来对模型做出更新的。对于大部分强化学习现实场景(例如电子游戏或者一些复杂物理环境),其马尔可夫决策过程的状态转移概率是无法写出来的,也就无法直接进行动态规划。
在这种情况下,智能体只能和环境进行交互,通过采样到的数据来学习,这类学习方法统称为无模型的强化学习(model-free reinforcement learning)。
不同于动态规划算法,无模型的强化学习算法不需要事先知道环境的奖励函数和状态转移函数,而是直接使用和环境交互的过程中采样到的数据来学习,这使得它可以被应用到一些简单的实际场景中。
本节中涉及到的强化学习中的两种经典算法:Sarsa 和Q-learning,都属无模型的强化学习算法。
3.1.2 时序差分思想¶
时序差分(Temporal-Difference)是一种用来估计一个策略的价值函数的方法。
例如,你要评估你现在的总资产状况。
-
之前的预期是1000元
-
现状:目前你的口袋里刚刚实际上收到了 500元 现金(\(r_t\))
-
未来预期:你手里还有一张欠条,上面写着朋友明年会还你 1000元(\(V(S_{t+1})\))
-
折扣系数:明年的 1000 元不等于现在的 1000 元(因为有通货膨胀,或者你本来可以用这笔钱去理财赚利息,又或者朋友可能会赖账),假设我们认为明年的钱只值现在的 90%,那么 \(\gamma = 0.9\)
-
TD更新:
\(\text{当前总价值} = 500\text{元 (落袋为安)} + 0.9 \times 1000\text{元 (未来的折算)} = 1400\text{元}\)
\(时序差分误差=当前总价值-之前预期的总价值=1400-1000=400元\)
时序差分结合了蒙特卡洛和动态规划算法的思想。
- 时序差分方法和蒙特卡洛的相似之处在于可以从样本数据中学习,不需要事先知道环境;
- 和动态规划的相似之处在于可以根据贝尔曼方程的思想,利用后续状态的价值估计来更新当前状态的价值估计。
回顾一下蒙特卡洛方法对价值函数的增量更新方式:
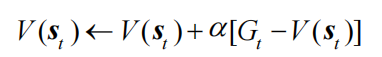
蒙特卡洛方法必须要等整个序列采样结束之后才能计算得到这一次的回报Gt,而时序差分算法只需要当前步结束即可进行计算。具体来说,时序差分算法用当前获得的奖励加上下一个状态的价值估计来作为在当前状态会获得的回报,即:
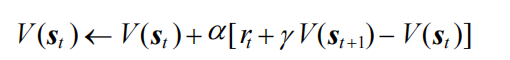
这里用了\(r_t + \gamma V(s_{t+1})\)来代替Gt,其中 $$ r_t + \gamma V(s_{t+1}) - V(s_t) $$通常被称为时序差分(temporal difference,TD)误差( error),时序差分算法将其与步长的乘积作为状态价值的更新量。
3.2 Sarsa 算法¶
3.2.1 Sarsa 算法原理¶
既然我们可以用时序差分算法来估计状态价值函数,那一个很自然的问题是,我们能否用类似策略迭代的方法来进行强化学习。策略评估已经可以通过时序差分算法实现,那么在不知道奖励函数和状态转移函数的情况下该怎么进行策略提升呢?答案是可以直接用时序差分算法来估计动作价值函数Q
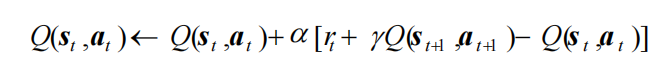
然后我们用贪婪算法来选取在某个状态下动作价值最大的那个动作,即
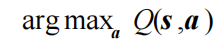
这样似乎已经形成了一个完整的强化学习算法:用贪婪算法根据动作价值选取动作来和环境交互,再根据得到的数据用时序差分算法更新动作价值估计。
不过还需考虑两个问题:
-
问题一:如果要用时序差分算法来准确地估计策略的状态价值函数,我们需要用极大量的样本来进行更新。
-
解决:实际上我们可以忽略这一点,直接用一些样本来评估策略,然后就可以更新策略
-
问题二:如果在策略提升中一直根据贪婪算法得到一个确定性策略,可能会导致某些状态动作对(s, a) 永远没有在序列中出现,以至于无法对其动作价值进行估计,进而无法保证策略提升后的策略比之前的好
-
解决:MAB算法中有一个ε -贪婪策略:有1− ε 的概率采用动作价值最大的那个动作,另外有ε 的概率从动作空间中随机采取一个动作。参考此思路,计算公式如下:
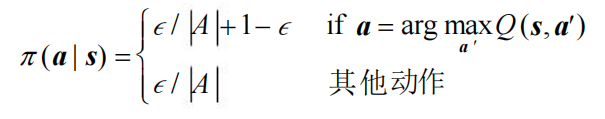
最终,得到一个实际的基于时序差分算法的强化学习算法。该算法的动作价值更新用到了当前状态 s、当前动作 a 、获得的奖励r 、下一个状态 s′ 和下一个动作a′ ,将这些符号拼接后就得到了算法名称—Sarsa。Sarsa算法的具体流程如下:

3.2.1 Sarsa 算法代码实现¶
- 悬崖漫步环境介绍
为了实现强化学习,我们先准备一个强化学习的环境,这里我们准备的是悬崖漫步环境。
悬崖漫步是一个非常经典的强化学习环境,它要求一个智能体从起点出发,避开悬崖行走,最终到达目标位置。如下图所示:
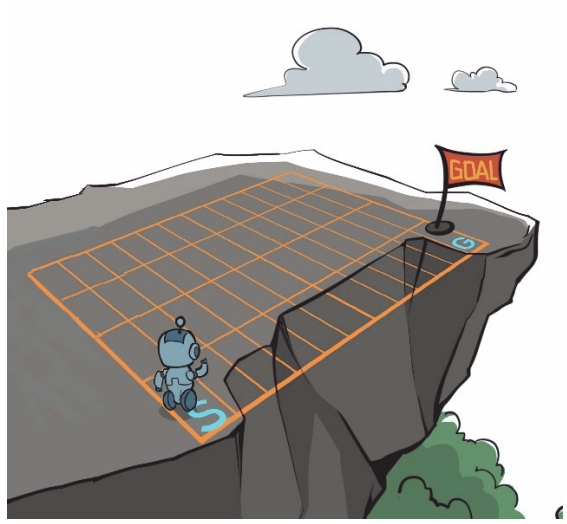
解释:有一个 4×12的网格世界,每一个网格表示一个状态。智能体的起点是左下角的状态,目标是右下角的状态,智能体在每一个状态都可以采取 4 种动作:上、下、左、右。如果智能体采取动作后触碰到边界墙壁则状态不发生改变,否则就会相应到达下一个状态。环境中有一段悬崖,智能体掉入悬崖或到达目标状态都会结束动作并回到起点,也就是说掉入悬崖或者达到目标状态是终止状态。智能体每走一步的奖励是−1,掉入悬崖的奖励是−100。
-
定义悬崖漫步环境
-
注意:
- 坐标原点 (0, 0) 定义在网格的左上角, 因此向右移动时列(x轴)增加,向下移动时行(y轴)增加
- 该网格,通常用二维坐标(x,y)表示一个位置,x对应列方向(水平方向),y对应行方向(垂直方向)
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm # tqdm 是显示循环进度条的库
class CliffWalkingEnv:
"""悬崖漫步环境"""
def __init__(self, ncol, nrow):
self.ncol = ncol # 定义网格世界的列
self.nrow = nrow # 定义网格世界的行
self.x = 0 # 记录当前智能体位置的横坐标
self.y = self.nrow - 1 # 记录当前智能体位置的纵坐标
def step(self, action): # 外部调用这个函数来改变当前位置
# 坐标原点 (0, 0) 被定义在网格的左上角, 因此向右移动时列(x轴)增加,向下移动时行(y轴)增加
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
# 4种动作, change[0]:上, change[1]:下, change[2]:左, change[3]:右。
# 如果当前状态不在悬崖或终点(即正常移动状态),则根据动作计算下一个位置的坐标
# 注意这里的网格世界,通常用二维坐标(x,y)表示一个位置,x对应列方向(即水平方向),y对应行方向(即垂直方向)
self.x = min(self.ncol - 1, max(0, self.x + change[action][0])) # 计算新的列坐标,防止越界,确保在0到ncol-1之间
self.y = min(self.nrow - 1, max(0, self.y + change[action][1])) # 计算新的行坐标,防止越界,确保在0到nrow-1之间
next_state = self.y * self.ncol + self.x # 将二维坐标转换为一维状态编号
reward = -1 # 默认每一步的奖励为-1(时间成本)
done = False # 默认此步不会结束回合
if self.y == self.nrow - 1 and self.x > 0: # 下一个位置在悬崖或者目标
done = True
if self.x != self.ncol - 1: # 下一个位置在悬崖
reward = -100
return next_state, reward, done
def reset(self): # 回归初始状态,坐标轴原点在左上角
self.x = 0
self.y = self.nrow - 1
return self.y * self.ncol + self.x
- 定义Sarsa 算法
实现 Sarsa 算法,主要维护一个表格 Q_table(),用来存储当前策略下所有状态动作对的价值,在用Sarsa 算法和环境交互时,用 ε -贪婪策略进行采样,在更新Sarsa 算法时,使用时序差分算法的公式。我们默认终止状态时所有动作的价值都是0 ,这些价值在初始化为0后就不会进行更新。
class Sarsa:
"""Sarsa 算法"""
def __init__(self, ncol, nrow, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros([nrow * ncol, n_action]) # 初始化Q(s,a)表格
self.n_action = n_action # 动作个数
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略中的参数
def take_action(self, state): # 选取下一步的操作,具体实现为 epsilon-贪婪
if np.random.random() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state): # 用于打印策略
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action): # 若两个动作的价值一样,都会记录下来
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1, a1):
td_error = r + self.gamma * self.Q_table[s1, a1] - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
- 在悬崖漫步环境运行Sarsa算法
接下来我们就在悬崖漫步环境中运行Sarsa 算法,查看运行结果
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm # tqdm 是显示循环进度条的库
ncol = 12
nrow = 4
env = CliffWalkingEnv(ncol, nrow)
np.random.seed(0)
epsilon = 0.1
alpha = 0.1
gamma = 0.9
agent = Sarsa(ncol, nrow, epsilon, alpha, gamma)
num_episodes = 500 # 智能体在环境中运行的序列的数量
return_list = [] # 记录每一条序列的回报
for i in range(10): # 显示 10 个进度条
# tqdm 的进度条功能
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个进度条的序列数
episode_return = 0
state = env.reset()
action = agent.take_action(state)
done = False
while not done:
next_state, reward, done = env.step(action)
next_action = agent.take_action(next_state)
episode_return += reward # 这里回报的计算不进行折扣因子衰减
agent.update(state, action, reward, next_state, next_action)
state = next_state
action = next_action
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0: # 每 10 条序列打印一下这 10 条序列的平均回报
pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Sarsa on {}'.format('Cliff Walking'))
plt.show()
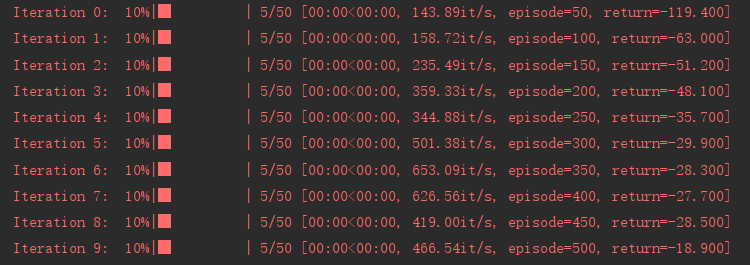
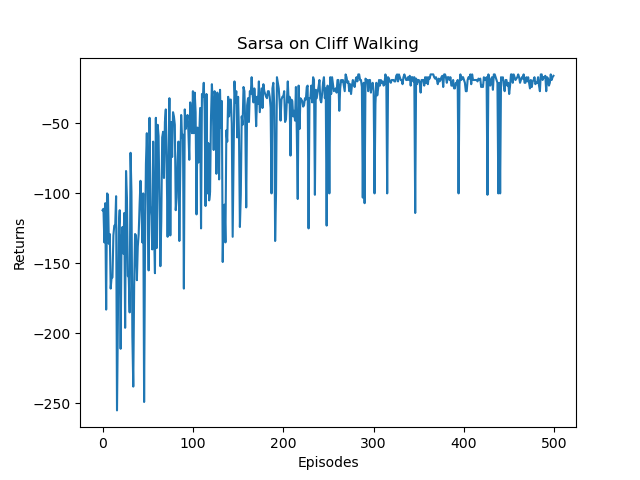
我们发现,随着训练的进行,Sarsa 算法获得的回报越来越高。在进行500 条序列的学习后,可以获得−20左右的回报,此时已经非常接近最优策略了。然后我们看一下 Sarsa算法得到的策略在各个状态下会使智能体采取什么样的动作。
def print_agent(agent, env, action_meaning, disaster=[], end=[]):
for i in range(env.nrow):
for j in range(env.ncol):
if (i * env.ncol + j) in disaster: # 灾难状态列表,对应位置会打印 ****
print('****', end=' ')
elif (i * env.ncol + j) in end: # 终点状态列表,对应位置会打印 EEEE
print('EEEE', end=' ')
else:
a = agent.best_action(i * env.ncol + j)
pi_str = ''
for k in range(len(action_meaning)): # 最佳动作会打印出来,不是最优选择的动作用o表示
pi_str += action_meaning[k] if a[k] > 0 else 'o'
print(pi_str, end=' ')
print()
action_meaning = ['^', 'v', '<', '>']
print('Sarsa 算法最终收敛得到的策略为:')
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
# Sarsa 算法最终收敛得到的策略为:
# ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
# ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
# ^ooo ooo> ^ooo ooo> ooo> ooo> ooo> ^ooo ^ooo ooo> ooo> ovoo
# ^ooo **** **** **** **** **** **** **** **** **** **** EEEE
可以发现Sarsa 算法会采取比较远离悬崖的策略(向右或向上)来抵达目标
3.3 Q-learning 算法¶
3.3.1 在线策略学习(on-policy)和离线策略学习(off-policy)¶
前边学过的Sarsa算法是在线策略学习算法,Sarsa 必须使用当前ε-贪婪策略采样得到的数据,因为它的更新中用到的Q(s′,a′)中的 a′ 是当前策略在s′ 下的动作,它更新时依赖于实际选择的动作和当前策略。而Q-learning是一种离线策略学习算法。
-
在线策略学习:要求使用在当前策略下采样得到的样本进行学习,一旦策略被更新,当前的样本就被放弃了,就好像在水龙头下用自来水洗手;
-
离线策略学习:使用经验回放池将之前采样得到的样本收集起来再次利用,就好像使用脸盆接水后洗手。
3.3.2 Q-learning算法原理¶
Q-learning 是强化学习中一种非常经典的 离线策略(Off-policy)算法,它通过 Q值(动作价值函数) 来衡量每个状态-动作对的质量。Q值表示在某个状态下采取某个动作所能获得的预期累积奖励。
Q-learning 的时序差分更新公式为:
\(Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_{t} + \gamma \max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \right]\)
其中:
-
\(Q(s_t, a_t)\):在状态 \(s_t\) 下选择动作 \(a_t\) 的Q值。
-
\(r_t\):执行动作 \(a_t\) 后,从状态 \(s_t\)到状态 \(s_{t+1}\) 所获得的即时奖励。
-
γ (gamma):折扣因子,控制未来奖励的权重,通常 0 ≤ γ ≤ 1。
-
α (alpha):学习率,控制每次更新的幅度,通常 0 ≤ α ≤ 1。
-
\(\max_{a'} Q(s_{t+1}, a')\):在状态 \(s_{t+1}\) 下选择最优动作的Q值。
通过对比Sarsa的公式,也容易发现二者的区别,公式整体很相似,关键区别只集中在“下一步价值的计算方式”上。
- Q-learning使用的是最优动作的Q值(\(\max_{a'} Q(s_{t+1}, a')\),也就是最大的Q值)
- Sarsa 使用的是实际执行动作的Q值(\(Q(s_{t+1}, a_{t+1})\))。
Q-learning 的更新是通过比较当前Q值与通过环境得到的即时奖励和未来奖励的预测值之间的差异来进行的。每次更新都会使 Q 值更接近于最优的 Q 值,最终通过多次更新,Q-learning 将收敛到最优的策略。
Q-learning算法的具体流程如下:

3.3.3 Q-learning算法代码实现¶
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm # tqdm 是显示循环进度条的库
class CliffWalkingEnv:
"""悬崖漫步环境"""
def __init__(self, ncol, nrow):
self.ncol = ncol # 定义网格世界的列
self.nrow = nrow # 定义网格世界的行
self.x = 0 # 记录当前智能体位置的横坐标
self.y = self.nrow - 1 # 记录当前智能体位置的纵坐标
def step(self, action): # 外部调用这个函数来改变当前位置
# 坐标原点 (0, 0) 被定义在网格的左上角, 因此向右移动时列(x轴)增加,向下移动时行(y轴)增加
change = [[0, -1], [0, 1], [-1, 0], [1, 0]]
# 4种动作, change[0]:上, change[1]:下, change[2]:左, change[3]:右。
# 如果当前状态不在悬崖或终点(即正常移动状态),则根据动作计算下一个位置的坐标
# 注意这里的网格世界,通常用二维坐标(x,y)表示一个位置,x对应列方向(即水平方向),y对应行方向(即垂直方向)
self.x = min(self.ncol - 1, max(0, self.x + change[action][0])) # 计算新的列坐标,防止越界,确保在0到ncol-1之间
self.y = min(self.nrow - 1, max(0, self.y + change[action][1])) # 计算新的行坐标,防止越界,确保在0到nrow-1之间
next_state = self.y * self.ncol + self.x # 将二维坐标转换为一维状态编号
reward = -1 # 默认每一步的奖励为-1(时间成本)
done = False # 默认此步不会结束回合
if self.y == self.nrow - 1 and self.x > 0: # 下一个位置在悬崖或者目标
done = True
if self.x != self.ncol - 1: # 下一个位置在悬崖
reward = -100
return next_state, reward, done
def reset(self): # 回归初始状态,坐标轴原点在左上角
self.x = 0
self.y = self.nrow - 1
return self.y * self.ncol + self.x
class QLearning:
""" Q-learning算法 """
def __init__(self, ncol, nrow, epsilon, alpha, gamma, n_action=4):
self.Q_table = np.zeros([nrow * ncol, n_action]) # 初始化Q(s,a)表格
self.n_action = n_action # 动作个数
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略中的参数
def take_action(self, state): # 选取下一步的操作
if np.random.random() < self.epsilon:
action = np.random.randint(self.n_action)
else:
action = np.argmax(self.Q_table[state])
return action
def best_action(self, state): # 用于打印策略
Q_max = np.max(self.Q_table[state])
a = [0 for _ in range(self.n_action)]
for i in range(self.n_action):
if self.Q_table[state, i] == Q_max:
a[i] = 1
return a
def update(self, s0, a0, r, s1):
td_error = r + self.gamma * self.Q_table[s1].max() - self.Q_table[s0, a0]
self.Q_table[s0, a0] += self.alpha * td_error
# 环境和智能体的初始化
ncol = 12
nrow = 4
env = CliffWalkingEnv(ncol, nrow)
np.random.seed(0)
epsilon = 0.1
alpha = 0.1
gamma = 0.9
agent = QLearning(ncol, nrow, epsilon, alpha, gamma)
num_episodes = 500 # 智能体在环境中运行的序列的数量
return_list = [] # 记录每一条序列的回报
for i in range(10): # 显示 10 个进度条
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)): # 每个进度条的序列数
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done = env.step(action)
episode_return += reward # 这里回报的计算不进行折扣因子衰减
agent.update(state, action, reward, next_state)
state = next_state
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0: # 每 10 条序列打印一下这 10 条序列的平均回报
pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
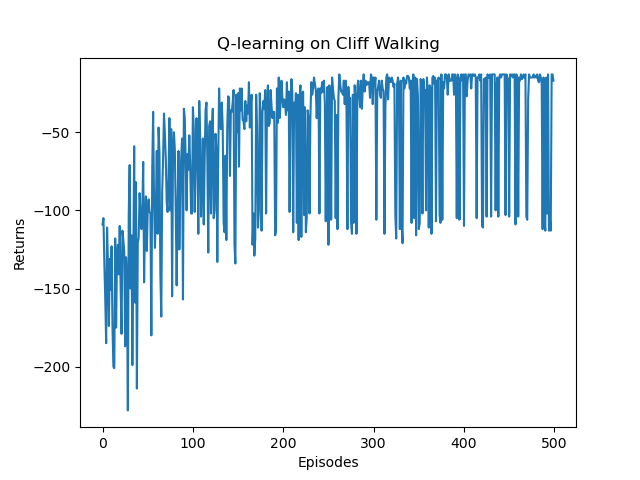
# 结果可视化
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Q-learning on {}'.format('Cliff Walking'))
plt.show()
def print_agent(agent, env, action_meaning, disaster=[], end=[]):
for i in range(env.nrow):
for j in range(env.ncol):
if (i * env.ncol + j) in disaster: # 灾难状态列表,对应位置会打印 ****
print('****', end=' ')
elif (i * env.ncol + j) in end: # 终点状态列表,对应位置会打印 EEEE
print('EEEE', end=' ')
else:
a = agent.best_action(i * env.ncol + j)
pi_str = ''
for k in range(len(action_meaning)):
pi_str += action_meaning[k] if a[k] > 0 else 'o'
print(pi_str, end=' ')
print()
action_meaning = ['^', 'v', '<', '>']
print('Q-learning 算法最终收敛得到的策略为:')
print_agent(agent, env, action_meaning, list(range(37, 47)), [47])
# Q-learning 算法最终收敛得到的策略为:
# ^ooo ovoo ovoo ^ooo ^ooo ovoo ooo> ^ooo ^ooo ooo> ooo> ovoo
# ooo> ooo> ooo> ooo> ooo> ooo> ^ooo ooo> ooo> ooo> ooo> ovoo
# ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
# ^ooo **** **** **** **** **** **** **** **** **** **** EEEE
作业¶
1.说明什么是蒙特卡洛方法
2.实现蒙特卡洛方法估计状态价值
3.说明动态规划的强化学习算法适用场景
4.说明什么是时序差分思想
5.动手实现Sarsa算法解决悬崖漫步环境问题
6.动手实现Q-learning算法解决悬崖漫步环境问题