强化学习入门¶
一、初识强化学习¶
学习目标:
1.了解强化学习的应用场景与发展历程
2.知道强化学习的架构
3.掌握强化学习的基础概念
1.1 强化学习应用场景¶
强化学习(Reinforcement Learning, RL)作为机器学习的一个重要分支,已经有越来越多的应用场景了。比如:
- 游戏对战:AlphaGo 在围棋中击败人类顶尖棋手,靠的就是不断对弈、积累经验。

- 自动驾驶:无人车在虚拟环境中“学会”如何刹车、避障、变道。

- 机器人控制:机械臂通过尝试,不断学会抓取物品或完成装配任务。

- 个性化推荐:视频网站/购物平台根据用户点击/停留行为,逐步优化推荐结果。
- 量化交易:智能代理通过市场反馈学习买卖策略。
1.2强化学习的发展¶
- 强化学习之父
Richard S. Sutton,他被广泛认为是强化学习(RL)领域的奠基人之一,因为他在理论研究和算法创新方面的突出贡献,尤其是对Q-learning、时序差分学习(TD Learning)和策略梯度等算法的开创性工作。与安德鲁·巴托共同获2024年图灵奖。

- 强化学习的发展历程
强化学习经历了“理论萌芽 → 算法突破 → 深度学习加持 → 走向现实”的过程。
- 早期探索(1950s–1980s)
- 灵感来自行为心理学的“条件反射”,机器尝试模仿人和动物的学习过程。
- 代表:Samuel 的西洋跳棋程序(1959)。
- 数学框架确立(1980s–1990s)
- Markov 决策过程(MDP)提出,为强化学习提供了理论基础。
- Q-learning(1989)出现,让 RL 有了标志性的算法。
- 深度学习结合(2010s)
- DeepMind 将深度神经网络与 RL 结合,提出 Deep Q-Network (DQN)。
- 2016 年 AlphaGo 横空出世,引发全球轰动。
- 现代发展(2020s)
- RL 与自然语言处理、大模型结合,用于 ChatGPT、自动驾驶、机器人学习等。
- “人类反馈强化学习(RLHF)”帮助 AI 更符合人类意图。
1.3 实际落地应用¶
目前,很多领域都已经有实际落地的强化学习应用了,比如:
-
工业制造:机器人自主调参,提高产线效率。
-
推荐系统:电商平台通过 RL 让推荐更“个性化”。
-
广告投放:根据实时点击反馈调整广告策略。
-
智慧交通:智能红绿灯通过 RL 减少拥堵。
-
能源管理:Google 用 RL 优化数据中心冷却系统,节能 40%。
-
医疗辅助:通过 RL 设计个性化治疗方案(如用药剂量控制)。
1.4 强化学习的定义¶
广泛地讲,强化学习是机器通过与环境交互来实现目标的一种计算方法。
详细解释:机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。
1.5 强化学习的架构¶
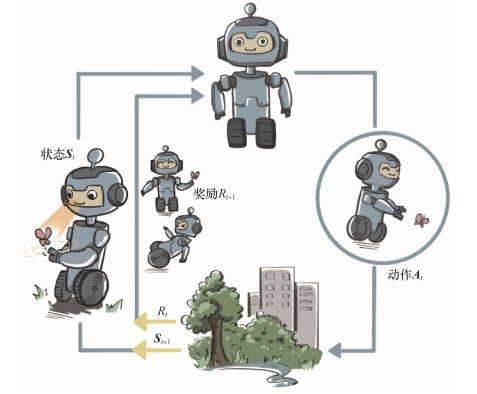
-
强化学习的两个实体:智能体(Agent)与环境(Environment)
-
强化学习中两个实体的交互:
- 状态空间S:S即为State,指环境中所有可能状态的集
- 动作空间A:A即为Action,指智能体所有可能动作的集合
- 奖励R:R即为Reward,指智能体在环境的某一状态下所获得的奖励。
以上图为例,智能体与环境的交互过程如下:
- 在 t 时刻,环境的状态为 St ,达到这一状态所获得的奖励为 Rt
- 智能体观测到 St 与 Rt ,采取相应动作 At
- 智能体采取 At 后,环境状态变为 St+1 ,得到相应的奖励 Rt+1
智能体在这个过程中学习,它的最终目标是:找到一个策略,这个策略根据当前观测到的环境状态和奖励反馈,来选择最佳的动作。
1.6 强化学习与监督学习的区别¶
- 核心概念:预测 vs. 决策
首先,我们需要区分“预测”与“决策”这两种行为的本质不同:
- 预测(Prediction):
- 性质:通常是被动的观测。
- 定义:根据输入数据产生一个信号,并期望该信号与未来可观测的事实一致。
- 后果:预测本身不会改变环境,也不会改变未来的情况。它是对现状或未来的“旁观”。
-
决策(Decision):
- 性质:通常是主动的交互。
- 定义:根据当前状态选择一个动作(Action)。
- 后果:决策往往伴随着后果(Consequences)。决策者的动作会改变环境的状态,从而影响未来的走向。因此,决策者必须对未来的结果负责。
-
关键场景:序贯决策(Sequential Decision Making)
在机器学习与现实生活中,最复杂的任务往往不是单次选择,而是序贯决策:
- 多轮交互:与预测任务通常是“单轮、独立”的(Independent and Identically Distributed, I.I.D.)不同,决策任务通常涉及与环境的多轮持续交互。
- 注:如果决策仅涉及单轮(即做完即止,无后续影响),它本质上可以退化为一个“判别最优动作”的预测任务。
-
长期规划:由于是多轮交互,智能体(Agent)必须具备全局视野。
- 当前轮次带来最大即时奖励的动作,从长远看未必是最优的(即“贪心策略”往往失效)。
- 决策者需要预判当前动作对未来环境的改变,并在后续的时间点做出进一步的调整。
-
监督学习 vs. 强化学习
-
监督学习(Supervised Learning)—— 面向“预测”
- 适用场景:处理独立的预测任务。
- 优化目标:寻找一个最优的模型函数,使其在训练数据集上最小化给定的损失函数(Loss Function),即让预测值尽可能接近真实标签。
- 强化学习(Reinforcement Learning)—— 面向“序贯决策”
- 适用场景:解决涉及多轮交互、由于动作导致环境变化的序贯决策任务。
- 优化目标:寻找一个最优策略(Policy),使其在与动态环境的交互过程中,最大化累积价值(Cumulative Value)或长期期望回报。
- 总结
| 维度 | 预测 (Prediction) / 监督学习 | 决策 (Decision) / 强化学习 |
|---|---|---|
| 交互轮次 | 单轮、独立任务 | 多轮、序贯任务 (Sequential) |
| 对环境影响 | 无(被动观测) | 有(主动改变环境状态) |
| 核心难点 | 拟合数据分布 | 权衡即时奖励与长期价值 |
| 优化目标 | 最小化误差/损失 (Minimize Loss) | 最大化长期价值 (Maximize Value) |
1.7 强化学习基础概念¶
为了方便理解接下来的基础概念,首先介绍一个大家耳熟能详的场景:“中国象棋”。在这个场景中,智能体(Agent)扮演红方棋手,与环境(黑方电脑对手或人类玩家)进行对弈。智能体的最终目标是找到一个“好”的策略,战胜黑方(即“将死”黑方的“将”)。
如果智能体熟读兵法(棋谱),知道每一步的最优解,那么赢得比赛可能并不难。但如果棋谱非常复杂,甚至智能体预先不知道任何象棋规则或战术,这项任务就变得极具挑战性。此时,智能体必须通过试错(trial and error)与环境(棋局和对手)交互来逐渐学会下棋并找到获胜的策略。接下来,我们结合中国象棋来了解强化学习中的核心概念。
1.7.1 状态和动作¶
- 状态(state):它描述了智能体相对于环境的状况。
在中国象棋中,状态对应于当前的棋盘局面(即所有棋子在棋盘上的位置分布),每一个不同的棋子排列组合都是一个独立的状态,我们将其索引为 \(s_1, s_2, \dots\)
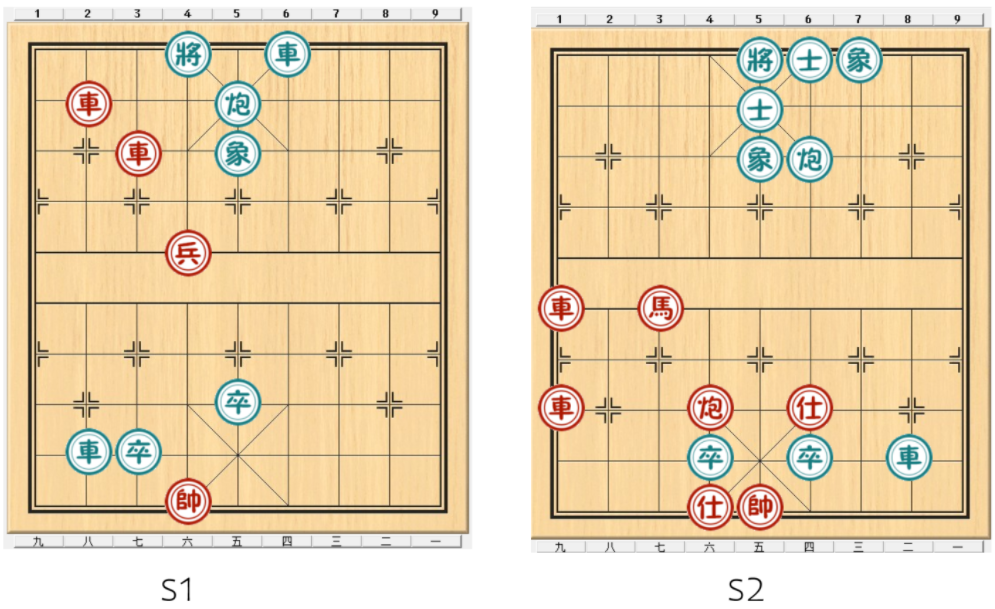
- 状态空间(state space):所有可能出现的棋局集合称为状态空间,记为 \(\mathcal{S}\)
象棋的状态空间非常巨大,这一数字在数学上被称为香农数,约为 \(10^{40}\) 以上
- 动作(actions):对于每个状态,智能体可以采取不同的动作。
在象棋中,动作指的是移动某个棋子到指定位置。例如:“炮二平五”、“马八进七”、“兵三进一”等。我们将这些动作记为 \(a_1, a_2, \dots\)。
- 动作空间(action space):所有动作的集合称为动作空间,记为 \(\mathcal{A}\)
需要注意的是,不同的状态(局面)下,可行的动作空间是不同的。例如,在开局状态 \(s_{start}\),红方只有“动兵”、“动炮”、“动马”等有限的合法动作;如果智能体试图在“别马腿”的情况下跳马,或者让“象”过河,这属于非法动作,动作空间通常只包含符合游戏规则的合法移动。
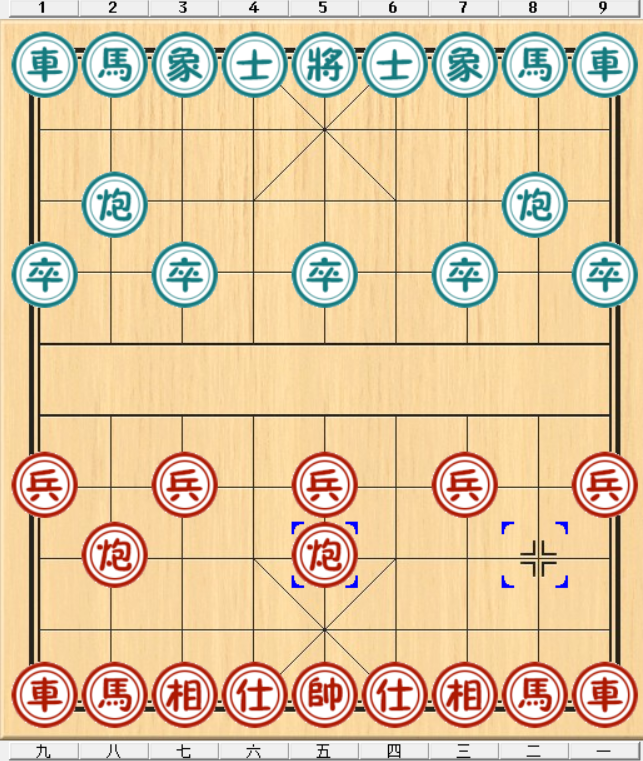
1.7.2 状态转移¶
当采取一个动作时,智能体可能会从一个状态移动到另一个状态。这个过程被称为状态转移(state transition)。
例如,当前状态 \(s_1\) 是初始布局,智能体采取动作 \(a_1\)(炮二平五),棋子位置改变,且轮到黑方应子。当黑方也走了一步后(如马八进七),棋盘变成了新的状态 \(s_2\)。这个过程表示为:\(s_1 \xrightarrow{a_1} s_2\)。
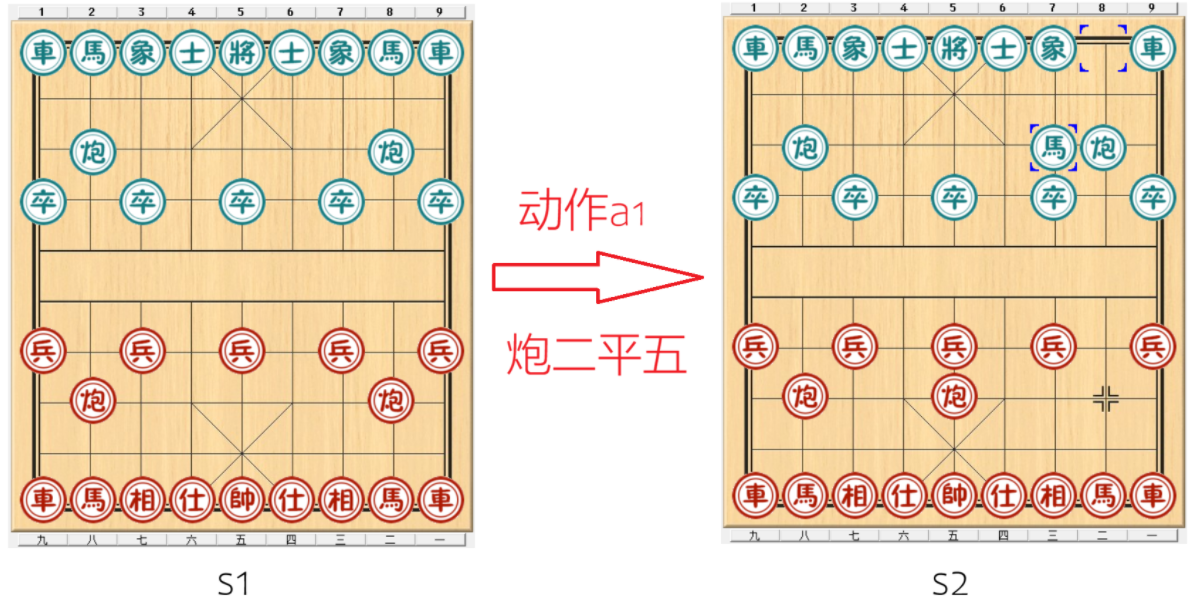
在数学上,状态转移可以用条件概率来描述。例如: \(\(p(s_2|s_1, a_1) \approx 1\)\) 这意味着在状态 \(s_1\) 下采取 \(a_1\),棋局大概率会变成 \(s_2\)(假设黑方的应对是可预测的)。
然而,状态转移通常是随机的(stochastic)或受对手影响的。因为对于红方的同一手棋(如炮二平五),黑方可能有多种应对方式(如马8进7,或炮8平5等)。黑方不同的应对会导致红方通过同一个动作 \(a_1\) 进入完全不同的下一个状态 \(s_{next}\)。因此,这必须由条件概率分布来描述, 例如
\(p(s_2|s_1, a_1) = 0.2\)
\(p(s_3|s_1, a_1) = 0.1\)
\(p(s_4|s_1, a_1) = 0.3\)
\(p(s_5|s_1, a_1) = 0.4\)
1.7.3 策略¶
策略(policy)告诉智能体在每个状态下采取什么动作。直观地说,策略就是一本“棋谱”或智能体的“大脑”。
在数学上,策略记为 \(\pi(a|s)\),这是一个为每一个棋局定义的条件概率分布函数。
-
确定性策略:例如在状态 \(s_1\)(开局),策略规定必须走“当头炮”。
\(\pi(\text{炮二平五}|s_1) = 1\)
\(\pi(\text{其他动作}|s_1) = 0\)
-
随机策略:在状态 \(s_1\),智能体可能觉得“飞相”和“上马”都不错,于是各有一半的概率。
\(\pi(\text{相三进五}|s_1) = 0.5\)
\(\pi(\text{马二进三}|s_1) = 0.5\)
策略也可以用表格表示法存储(尽管象棋的状态太多,存不下,但逻辑一样):每一行是一个特定的棋局,每一列是一个动作,表格中的值代表在该棋局下走这步棋的概率。
策略表:红方开局策略 \(\pi(a|s)\)
| 状态 (State) | 动作1 (\(a_1\)) 炮二平五 (当头炮) |
动作2 (\(a_2\)) 相三进五 (飞相局) |
动作3 (\(a_3\)) 兵七进一 (仙人指路) |
动作4 (\(a_4\)) 马二进三 (起马局) |
动作5 (\(a_5\)) 帅五进一 (老帅前进一步) |
|---|---|---|---|---|---|
| \(S_1\): 初始局面 (双方均未走棋) |
0.40 | 0.30 | 0.20 | 0.10 | 0.00 |
| \(S_2\): 黑方应对 (假设红炮二平五,黑马8进7后) |
0.05 | 0.00 | 0.15 | 0.80 | 0.00 |
1.7.4 奖励¶
在某个状态执行一个动作后,智能体获得一个奖励(记为 \(r\))作为来自环境的反馈。奖励是状态 \(s\) 和动作 \(a\) 的函数,记为 \(r(s, a)\)。它的值可以是正数、负数或零。不同的奖励对智能体最终学到的策略有不同的影响。一般来说,通过正奖励,我们鼓励智能体采取相应的动作。通过负奖励,我们阻止智能体采取该动作。
在中国象棋的例子中,奖励可以设计如下:
- 胜负奖励:如果这一步棋导致将死对方(获胜),设 \(r_{\text{win}} = +100\)。
- 失败惩罚:如果这一步棋导致被对方将死(失败),设 \(r_{\text{lose}} = -100\)。
- 违规惩罚:如果智能体试图走违规棋(如象过河),设 \(r_{\text{invalid}} = -10\)(并强制结束或重试)。
- 吃子奖励:如果这一步吃掉了对方的“车”,可能会给一个小的正奖励 \(r_{\text{eatcar}} = +5\)。
- 普通步:如果只是普通的一步棋,局势未分,通常设 \(r_{\text{step}} = 0\)。
即时奖励 vs 总奖励
思考:如果知道了奖励,我们是否可以通过简单地选择具有最大奖励的动作来找到好的策略?
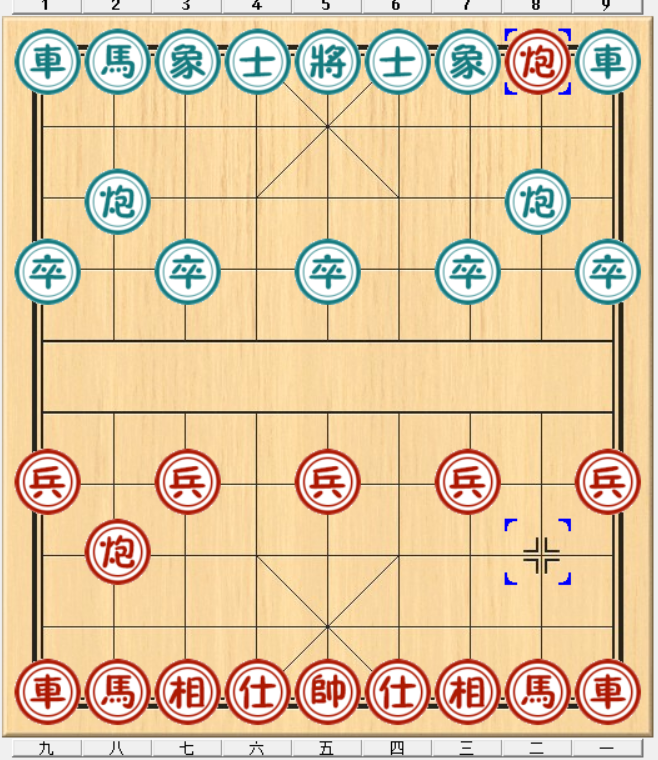
答案是否定的。
如果我们只看即时奖励(immediate rewards),智能体可能会变得“贪吃”。例如,某一步棋可以吃掉对方的“马”(即时奖励 +3),但随后会导致开局不利。 为了找到好策略,智能体不能只看眼前的利益,必须考虑总奖励(total reward)。有时候,为了最终的胜利(Checkmate),智能体需要做出“弃车保帅”或“弃子争先”的决策,这种决策即时奖励可能是负的(丢了子),但长期回报是最大的。
随机性奖励
前边我们设计的奖励是固定的, 但在更复杂的强化学习设置中,奖励往往包含随机性。在中国象棋中,如果我们把“对手”看作环境的一部分,同样的招法可能会因为对手水平不同(或对手的失误)而产生不同的反馈。
例如,红方在局面 \(s_{\text{trap}}\) 设下了一个“弃马陷阱”(动作 \(a_{\text{trap}}\)):这是一个赌博性的招法,如果对手上当,红方将获胜;如果对手看破,红方将白丢一子。
此时的奖励分布可能如下:
- 情况 A(对手上当):对手吃掉了诱饵,红方获得巨大优势。
\(p(r = +100 | s_{\text{trap}}, a_{\text{trap}}) = 0.3\)
- 情况 B(对手看破):对手没上当,红方白丢一个马,处于劣势。
\(p(r = -5 | s_{\text{trap}}, a_{\text{trap}}) = 0.7\)
这表明,在 \(s_{\text{trap}}\) 采取 \(a_{\text{trap}}\) 这一动作,有 30% 的概率获得大奖,有 70% 的概率受到惩罚。智能体需要根据这个概率分布来计算期望回报,从而决定是否要“冒险”。
1.7.5 轨迹、回报、折扣因子和回合¶
1.7.5.1 轨迹(trajectory)¶
轨迹(trajectory)是一条状态-动作-奖励链。
例如,一整盘对局的记录,即“状态-动作-奖励”的链条。
\(s_{start} \xrightarrow[r=0]{a_1} s_2 \xrightarrow[r=0]{a_2} s_3 \dots \xrightarrow[r=+100]{a_{win}} s_{end}\)
这意味着:开局 -> 红方走棋 -> 局势变化 -> 红方再走... -> 直到红方获胜。
1.7.5.2 回报(return)¶
这条轨迹的回报(return)定义为沿轨迹收集的所有奖励的总和:
\(\text{return} = r1 + r2 + r3 + r4...\)
回报也被称为总奖励(total rewards)或累积奖励(cumulative rewards)。
回报由即时奖励和未来奖励组成。这里,即时奖励是在初始状态采取动作后获得的奖励;未来奖励是指离开初始状态后获得的奖励。即时奖励可能为负,而未来奖励为正。因此,采取哪些动作应该由回报(即总奖励)决定,而不是由即时奖励决定,以避免短视的决策。
1.7.5.3 折扣因子(\(\gamma\))¶
在象棋中,虽然步数通常是有限的,但为了防止死循环(长将、长捉)或为了鼓励“快速获胜”,我们需要引入折扣因子 \(\gamma \in (0, 1)\)。
折扣回报(discounted return):
\(\text{discounted return} = r_1 + \gamma r_2 + \gamma^2 r_3 + \dots\)
- 如果 \(\gamma\) 接近 0,智能体是短视的,它更在意马上吃到对方的子,而不顾后果。
- 如果 \(\gamma\) 接近 1,智能体是远视的,它愿意为了最终的胜利(延迟的巨大奖励)而忍受暂时的平淡甚至丢子。
- 另外,由于 \(\gamma < 1\),第 100 步获胜的奖励打折后会比第 20 步获胜的奖励小。这会鼓励智能体寻找最快取胜的路径。
引入折扣因子有以下作用:
- 首先,它移除了停止标准并允许无限长的轨迹。
- 其次,折扣率可用于调整对近期或远期奖励的重视程度。特别是,如果 \(\gamma\) 接近 0,则智能体更重视在不久的将来获得的奖励。由此产生的策略将是短视的。如果 \(\gamma\) 接近 1,则智能体更重视远期的未来奖励。由此产生的策略是远视的,并且敢于冒在不久的将来获得负奖励的风险。
1.7.5.4 回合(episode)¶
当遵循策略与环境交互时,智能体可能会在某些终止状态(terminal states)停止。由此产生的轨迹称为一个回合(episode)(或一次试验(trial))。例如:在象棋中,从开局到终局(将死、认输或和棋)的过程就是一个回合。
如果环境或策略是随机的,从同一状态开始我们会获得不同的回合。如果一切都是确定性的,从同一状态开始我们将始终获得相同的回合。
通常假设一个回合是有限轨迹。具有回合的任务(如象棋)称为回合制任务(episodic tasks)。然而,有些任务可能没有终止状态(如自动驾驶),意味着与环境交互的过程永远不会结束。此类任务称为持续性任务(continuing tasks)。
二、多臂老虎机问题¶
学习目标:
1.通过多臂老虎机问题,理解强化学习中的一些概念:累计懊悔、估计期望奖励、探索、利用
2.1 多臂老虎机问题介绍¶
为了入门强化学习,我们先了解多臂老虎机问题(multi-armed bandit,MAB),它可以被看作简化版的强化学习问题。与强化学习不同,多臂老虎机不存在状态信息,只有动作和奖励,算是最简单的“和环境交互中的学习”的一种形式。多臂老虎机中的探索与利用(exploration vs. exploitation)问题一直以来都是一个特别经典的问题,理解它能够帮助我们学习强化学习。

有一个拥有 K 根拉杆的老虎机,拉动每一根拉杆都对应一个关于奖励的概率分布R。们每次拉动其中一根拉杆,就可以从该拉杆对应的奖励概率分布中获得一个奖励 r。我们在各根拉杆的奖励概率分布未知的情况下,从头开始尝试,目标是在操作 T 次拉杆后获得尽可能高的累积奖励。
由于奖励的概率分布是未知的,因此我们需要在“探索拉杆的获奖概率”和“根据经验选择获奖最多的拉杆”中进行权衡。“采用怎样的操作策略才能使获得的累积奖励最高”便是多臂老虎机问题。如果是你,会怎么做呢?
2.1.1 数学描述¶

2.1.2 累积懊悔¶
为了更加直观、方便地观察拉动一根拉杆的期望奖励离最优拉杆期望奖励的差距,我们引入懊悔(regret)概念。懊悔被定义为拉动当前拉杆的动作 a 与最优拉杆的期望奖励差,即R(a)=Q-Q(a*)。
累积懊悔(cumulative regret)即操作T次拉杆后累积的懊悔总量,对于一次完整的T步决策{a1,a2,.....aT} ,累积懊悔为
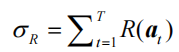
MAB 问题的目标为最大化累积奖励,等价于最小化累积懊悔。
2.1.3 估计期望奖励¶
为了知道拉动哪一根拉杆能获得更高的奖励,我们需要估计拉动这根拉杆的期望奖励。由于只拉动一次拉杆获得的奖励存在随机性,所以需要多次拉动一根拉杆,然后计算得到的多次奖励的期望,其算法流程如下所示。

上述循环体中的第四步,期望奖励估值等价于所有奖励的算数平均值
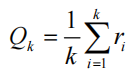
如果将所有数求和再除以次数,其缺点是每次更新的时间复杂度和空间复杂度均为O(n),以此采用增量式更新,时间复杂度和空间复杂度均为O(1)。
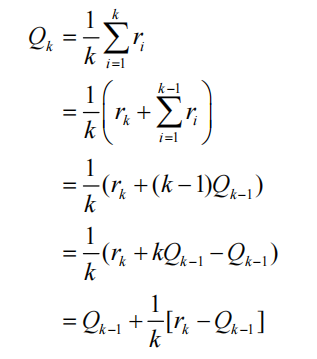
2.2 探索与利用的平衡¶
在多臂老虎机问题中,一个经典的问题就是探索与利用的平衡问题。
- 探索(exploration)是指尝试拉动更多可能的拉杆,这根拉杆不一定会获得最大的奖励,但这种方案能够摸清楚所有拉杆的获奖情况。例如,对于一个 10 臂老虎机,我们要把所有的拉杆都拉动一下才知道哪根拉杆可能获得最大的奖励。
- 利用(exploitation)是指拉动已知期望奖励最大的那根拉杆,由于已知的信息仅仅来自有限次的交互观测,所以当前的最优拉杆不一定是全局最优的。
于是在多臂老虎机问题中,设计策略时就需要平衡探索和利用的次数,使得累积奖励最大化。一个比较常用的思路是在开始时做比较多的探索,在对每根拉杆都有比较准确的估计后,再进行利用。
目前已有一些比较经典的算法来解决这个问题,例如ε -贪婪算法、上置信界算法和汤普森采样算法等
2.3 ε -贪婪算法¶
完全贪婪算法即在每一时刻采取期望奖励估值最大的动作(拉动拉杆),这就是纯粹的利用,而没有探索,所以我们通常需要对完全贪婪算法进行一些修改,其中比较经典的一种方法为ε -贪婪(ε -Greedy)算法。
ε -贪婪算法在完全贪婪算法的基础上添加了噪声,每次以概率1−ε 选择以往经验中期望奖励估值最大的那根拉杆(利用),以概率ε 随机选择一根拉杆(探索),公式如下:

2.3.1 定义多臂老虎机¶
首先定义一个拉杆数为 10 的多臂老虎机。其中拉动每根拉杆的奖励服从伯努利分布(Bernoulli distribution),即每次拉下拉杆有 p 的概率获得的奖励为 1,有 1 − p 的概率获得的奖励为 0。奖励为 1 代表获奖,奖励为 0 代表没有获奖。
import numpy as np
import matplotlib.pyplot as plt
class BernoulliBandit(object):
""" 伯努利多臂老虎机,输入K表示拉杆个数"""
def __init__(self, K):
self.probs = np.random.uniform(size=K) # 随机生成K个0-1的数,作为拉动每根拉杆的获奖概率
self.best_idx = np.argmax(self.probs) # 获奖概率最大的拉杆
self.best_prob = self.probs[self.best_idx] # 最大的获奖概率
self.K = K
def step(self, k):
# 当玩家选择了k号拉杆后,根据拉动该老虎机的k号拉杆获得奖励的概率返回1(获奖)或0(未获奖)
if np.random.random() < self.probs[k]:
return 1
else:
return 0
np.random.seed(1) # 设定随机种子,使实验具有可重复性
K = 10
bandit_10_arm = BernoulliBandit(K)
print("随机生成了一个%d臂伯努利老虎机" % K)
print("获奖概率最大的拉杆的获奖概率为%d号,其获奖概率为%.4f" % (bandit_10_arm.best_idx, bandit_10_arm.best_prob))
2.3.2 定义多臂老虎机求解基类¶
class Solver(object):
""" 多臂老虎机算法基本框架"""
def __init__(self, bandit):
self.bandit = bandit
self.counts = np.zeros(self.bandit.K) # 每根拉杆的尝试次数
self.regret = 0. # 当前算法的累积懊悔
self.actions = [] # 维护一个列表,记录每一步的动作
self.regrets = [] # 维护一个列表,记录每一步的累积懊悔
def update_regret(self, k):
# 计算累积懊悔并保存,k为本次动作选择的拉杆的编号
self.regret += self.bandit.best_prob - self.bandit.probs[k]
self.regrets.append(self.regret)
def run_one_step(self):
# 返回当前动作选择哪一根拉杆,有每个具体的策略实现
raise NotImplementedError
def run(self, num_steps):
# 运行一定次数,num_steps为运行总次数
for _ in range(num_steps):
k = self.run_one_step()
self.counts[k] += 1
self.actions.append(k)
self.update_regret(k)
2.3.3 实现ε -贪婪算法¶
- (1)ε -贪婪算法实现
class EpsilonGreedy(Solver):
"""epsilon贪婪算法, 继承Solver类"""
def __init__(self, bandit, epsilon=0.01, init_prob=1.0):
super(EpsilonGreedy, self).__init__(bandit)
self.epsilon = epsilon
# 初始化拉动所有拉杆的期望奖励估值
self.estimates = np.array([init_prob] * self.bandit.K)
def run_one_step(self):
if np.random.random() < self.epsilon:
k = np.random.randint(0, self.bandit.K) # 随机选择一根拉杆
else:
k = np.argmax(self.estimates) # 选择当前最 optimial 的拉杆
r = self.bandit.step(k)
self.estimates[k] += 1. / (self.counts[k] + 1) * (r - self.estimates[k])
return k
def plot_results(solvers, solver_names):
"""
生成累积懊悔随时间变化的图像,输入solvers是一个列表,列表中的每一个元素是一种特定的策略。
而solver_names也是一个列表,存储每个策略的名称
"""
for idx, solver in enumerate(solvers):
time_list = range(len(solver.regrets))
plt.plot(time_list, solver.regrets, label=solver_names[idx])
plt.xlabel('Time steps')
plt.ylabel('Cumulative regrets')
plt.title('%d-armed bandit' % solvers[0].bandit.K)
plt.legend()
plt.show()
if __name__ == '__main__':
# 1.epsilon
np.random.seed(1)
epsilon_greedy_solver = EpsilonGreedy(bandit_10_arm, epsilon=0.01)
epsilon_greedy_solver.run(5000)
print('epsilon-贪婪算法的累积懊悔为:', epsilon_greedy_solver.regret)
plot_results([epsilon_greedy_solver], ['EpsilonGreedy'])
- (2)不同epsilon参数值的比较
if __name__ == '__main__':
# # 1.epsilon
# np.random.seed(1)
# epsilon_greedy_solver = EpsilonGreedy(bandit_10_arm, epsilon=0.01)
# epsilon_greedy_solver.run(5000)
# print('epsilon-贪婪算法的累积懊悔为:', epsilon_greedy_solver.regret)
# plot_results([epsilon_greedy_solver], ['EpsilonGreedy'])
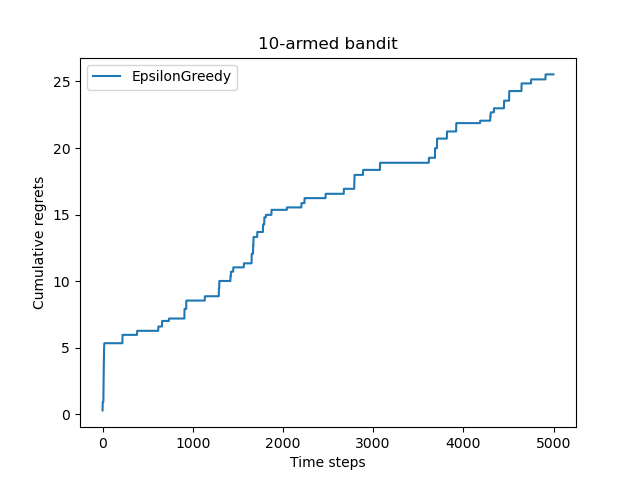
# 2.不同epsilon参数值的比较
np.random.seed(0)
epsilons = [1e-4, 0.01, 0.1, 0.25, 0.5]
epsilon_greedy_solver_list = [EpsilonGreedy(bandit_10_arm, epsilon=e) for e in epsilons]
epsilon_greedy_solver_names = ["epsilon={}".format(e) for e in epsilons]
for solver in epsilon_greedy_solver_list:
solver.run(5000)
plot_results(epsilon_greedy_solver_list, epsilon_greedy_solver_names)
- (3)时间衰减的ε -贪婪算法
随着探索次数的不断增加,我们对各个动作的奖励估计得越来越准,此时我们就没必要继续花大力气进行探索。所以在ε -贪婪算法的具体实现中,我们可以令ε 随时间衰减,即探索的概率将会不断降低。接下来我们尝试ε 值随时间衰减的ε -贪婪算法,采取的具体衰减形式为反比例衰减,公式为ε(t) = 1/t
class DecayingEpsilonGreedy(Solver):
""" epsilon值随时间衰减的epsilon-贪婪算法,继承Solver类 """
def __init__(self, bandit, init_prob=1.0):
super(DecayingEpsilonGreedy, self).__init__(bandit)
self.estimates = np.array([init_prob] * self.bandit.K)
self.total_count = 0
def run_one_step(self):
self.total_count += 1
if np.random.random() < 1 / self.total_count: # epsilon值随时间衰减
k = np.random.randint(0, self.bandit.K)
else:
k = np.argmax(self.estimates)
r = self.bandit.step(k)
self.estimates[k] += 1. / (self.counts[k] + 1) * (r - self.estimates[k])
return k
if __name__ == '__main__':
# # 1.epsilon
# np.random.seed(1)
# epsilon_greedy_solver = EpsilonGreedy(bandit_10_arm, epsilon=0.01)
# epsilon_greedy_solver.run(5000)
# print('epsilon-贪婪算法的累积懊悔为:', epsilon_greedy_solver.regret)
# plot_results([epsilon_greedy_solver], ['EpsilonGreedy'])
# # 2.不同epsilon参数值的比较
# np.random.seed(0)
# epsilons = [1e-4, 0.01, 0.1, 0.25, 0.5]
# epsilon_greedy_solver_list = [EpsilonGreedy(bandit_10_arm, epsilon=e) for e in epsilons]
# epsilon_greedy_solver_names = ["epsilon={}".format(e) for e in epsilons]
# for solver in epsilon_greedy_solver_list:
# solver.run(5000)
# plot_results(epsilon_greedy_solver_list, epsilon_greedy_solver_names)
# 3.时间衰减的epsilon-贪婪算法
np.random.seed(1)
decaying_epsilon_greedy_solver = DecayingEpsilonGreedy(bandit_10_arm)
decaying_epsilon_greedy_solver.run(5000)
print('epsilon 值衰减的贪婪算法的累积懊悔为:', decaying_epsilon_greedy_solver.regret)
plot_results([decaying_epsilon_greedy_solver], ["DecayingEpsilonGreedy"])
# epsilon 值衰减的贪婪算法的累积懊悔为:10.114334931260183
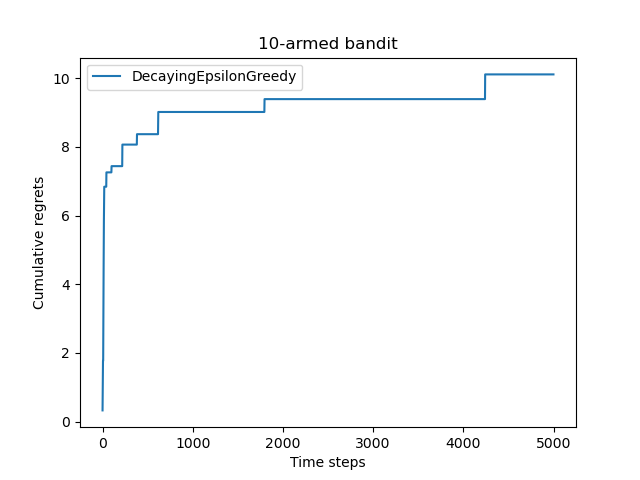
上图中,随时间做反比例衰减的ε -贪婪算法能够使累积懊悔与时间步的关系变成次线性(sublinear)的,这明显优于固定ε 值的ε -贪婪算法。
2.4 上置信界算法(了解)¶
设想这样一种情况:对于一台双臂老虎机,其中第一根拉杆只被拉动过一次,得到的奖励为 0 ;第二根拉杆被拉动过很多次,我们对它的奖励分布已经有了大致的把握。这时你会怎么做?或许你会进一步尝试拉动第一根拉杆,从而更加确定其奖励分布。这种思路主要是基于不确定性,因为此时第一根拉杆只被拉动过一次,它的不确定性很高。
一根拉杆的不确定性越大,它就越具有探索的价值,因为探索之后我们可能发现它的期望奖励很大。因此我们引入不确定性度量U( a),它会随着一个动作被尝试次数的增加而减小。我们可以使用一种基于不确定性的策略来综合考虑现有的期望奖励估值和不确定性,其核心问题是如何估计不确定性。
上置信界(upper confidence bound,UCB)算法是一种经典的基于不确定性的策略算法,它的思想是选取期望奖励上界最大的动作,公式如下:
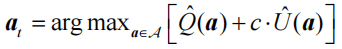
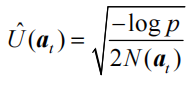
式中:
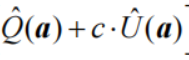 表示期望奖励上界
表示期望奖励上界-
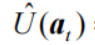 表示不确定性度量
表示不确定性度量 -
c是系数
UCB 算法在每次选择拉杆前,先估计拉动每根拉杆的期望奖励上界,使得拉动每根拉杆的期望奖励只有一个较小的概率 p 超过这个上界,接着选出期望奖励上界最大的拉杆,从而选择最有可能获得最大期望奖励的拉杆。
令p=1/t,并且在分母中为拉动每根拉杆的次数加上常数 1,以免出现分母为 0 的情形,得到不确定性度量的最终公式:
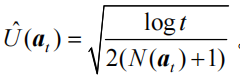
代码实现:
class UCB(Solver):
""" UCB算法,继承Solver类 """
def __init__(self, bandit, coef, init_prob=1.0):
super(UCB, self).__init__(bandit)
self.total_count = 0
self.estimates = np.array([init_prob] * self.bandit.K)
self.coef = coef
def run_one_step(self):
self.total_count += 1
ucb = self.estimates + self.coef * np.sqrt(np.log(self.total_count) / (2 * (self.counts + 1))) # 计算上置信界
k = np.argmax(ucb) # 选出上置信界最大的拉杆
r = self.bandit.step(k)
self.estimates[k] += 1. / (self.counts[k] + 1) * (r - self.estimates[k])
return k
if __name__ == '__main__':
# # 1.epsilon
# np.random.seed(1)
# epsilon_greedy_solver = EpsilonGreedy(bandit_10_arm, epsilon=0.01)
# epsilon_greedy_solver.run(5000)
# print('epsilon-贪婪算法的累积懊悔为:', epsilon_greedy_solver.regret)
# plot_results([epsilon_greedy_solver], ['EpsilonGreedy'])
# # 2.不同epsilon参数值的比较
# np.random.seed(0)
# epsilons = [1e-4, 0.01, 0.1, 0.25, 0.5]
# epsilon_greedy_solver_list = [EpsilonGreedy(bandit_10_arm, epsilon=e) for e in epsilons]
# epsilon_greedy_solver_names = ["epsilon={}".format(e) for e in epsilons]
# for solver in epsilon_greedy_solver_list:
# solver.run(5000)
# plot_results(epsilon_greedy_solver_list, epsilon_greedy_solver_names)
# # 3.时间衰减的epsilon-贪婪算法
# np.random.seed(1)
# decaying_epsilon_greedy_solver = DecayingEpsilonGreedy(bandit_10_arm)
# decaying_epsilon_greedy_solver.run(5000)
# print('epsilon 值衰减的贪婪算法的累积懊悔为:', decaying_epsilon_greedy_solver.regret)
# plot_results([decaying_epsilon_greedy_solver], ["DecayingEpsilonGreedy"])
# # epsilon 值衰减的贪婪算法的累积懊悔为:10.114334931260183
# 4.上置信界算法
np.random.seed(1)
coef = 1 # 控制不确定性比重的系数
UCB_solver = UCB(bandit_10_arm, coef)
UCB_solver.run(5000)
print('上置信界算法的累积懊悔为:', UCB_solver.regret)
plot_results([UCB_solver], ["UCB"])
# 上置信界算法的累积懊悔为:4.360254345326592
2.5 汤普森采样算法(了解)¶
MAB 中还有一种经典算法—汤普森采样(Thompson sampling),先假设拉动每根拉杆的奖励服从一个特定的概率分布,然后根据拉动每根拉杆的期望奖励来进行选择。但是由于计算所有拉杆的期望奖励的代价比较高,汤普森采样算法使用采样的方式,即根据当前每个动作 a 的奖励概率分布进行一轮采样,得到一组各根拉杆的奖励样本,再选择样本中奖励最大的动作。(可以看出,汤普森采样是一种计算所有拉杆的最高奖励概率的蒙特卡洛采样方法,这种方法后续课程会展开介绍)。
2.5.1 Beta分布介绍¶
Beta分布是定义在 [0,1] 区间上的连续概率分布,由两个正形状参数 α(alpha)和 β(beta) 控制。其核心用途是建模概率或比例的不确定性。
- 概率密度函数(PDF)

其中的伽马函数,当x 为正整数时,Г ( x ) = ( x − 1 ) !
- 数学特征
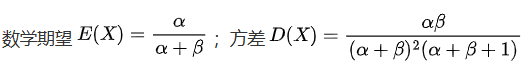
- 形状特点
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
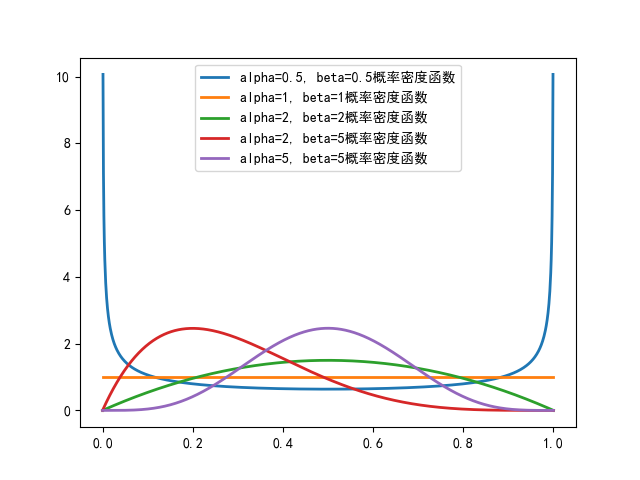
params = ((0.5, 0.5), (1, 1), (2, 2), (2, 5), (5, 5))
for param in params:
alpha, beta_param = param
# 生成概率密度函数
x = np.linspace(0, 1, 1000)
pdf = beta.pdf(x, alpha, beta_param)
plt.plot(x, pdf, lw=2, label=f'alpha={alpha}, beta={beta_param}概率密度函数')
plt.legend()
plt.show()
随α 、β 取值不同形状有差异
- α>1, β >1时单峰;
- α<1, β <1呈 “U” 型
- α=β=1 时退化为 [0,1]上的均匀分布
- α<β,右偏(左高右低的长尾)
- α>β,左偏(右高左低的长尾)
2.5.2 实现汤普森采样¶
了解了汤普森采样算法的基本思路后,我们需要解决另一个问题:怎样得到当前每个动作a 的奖励概率分布并且在过程中进行更新?
在实际情况中,我们通常用 Beta 分布对当前每个动作的奖励概率分布进行建模。具体来说,若某拉杆被选择了 k 次,其中 m1 次奖励为 1,m2 次奖励为 0,则该拉杆的奖励服从参数为 (m1+1, m2+1) 的 Beta 分布。
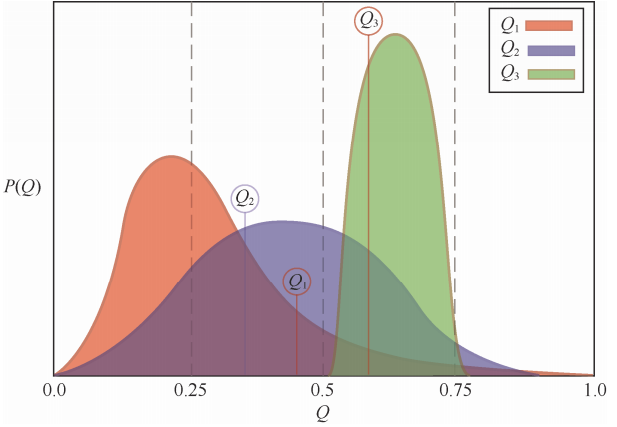
汤普森采样示例如下图所示:
- Q1,Q2,Q3 分别代表三个候选动作(例如,多臂老虎机中的三个不同拉杆)的潜在奖励概率值
- 对于某个动作a,
Qₐ表示该动作被选择时获得奖励(例如奖励为1)的未知真实概率。在汤普森采样中,我们不直接知道这个真实概率值Qₐ是多少,但是我们会用一个概率分布(Beta分布) 来描述我们对Qₐ可能取值的置信程度(或不确定性)
- 对于某个动作a,
- P(Q)是概率密度函数, 表示横轴上某个特定的 Q值(动作的潜在奖励概率)出现的概率密度
class ThompsonSampling(Solver):
""" 汤普森采样算法,继承Solver类 """
def __init__(self, bandit):
super(ThompsonSampling, self).__init__(bandit)
self._a = np.ones(self.bandit.K) # 列表,表示每根拉杆奖励为1的次数
self._b = np.ones(self.bandit.K) # 列表,表示每根拉杆奖励为0的次数
def run_one_step(self):
samples = np.random.beta(self._a, self._b) # 按照Beta分布采样一组奖励样本
k = np.argmax(samples) # 选出采样奖励最大的拉杆
r = self.bandit.step(k)
self._a[k] += r # 更新Beta分布的第一个参数
self._b[k] += (1 - r) # 更新Beta分布的第二个参数
return k
if __name__ == '__main__':
# # 1.epsilon
# np.random.seed(1)
# epsilon_greedy_solver = EpsilonGreedy(bandit_10_arm, epsilon=0.01)
# epsilon_greedy_solver.run(5000)
# print('epsilon-贪婪算法的累积懊悔为:', epsilon_greedy_solver.regret)
# plot_results([epsilon_greedy_solver], ['EpsilonGreedy'])
# # 2.不同epsilon参数值的比较
# np.random.seed(0)
# epsilons = [1e-4, 0.01, 0.1, 0.25, 0.5]
# epsilon_greedy_solver_list = [EpsilonGreedy(bandit_10_arm, epsilon=e) for e in epsilons]
# epsilon_greedy_solver_names = ["epsilon={}".format(e) for e in epsilons]
# for solver in epsilon_greedy_solver_list:
# solver.run(5000)
# plot_results(epsilon_greedy_solver_list, epsilon_greedy_solver_names)
# # 3.时间衰减的epsilon-贪婪算法
# np.random.seed(1)
# decaying_epsilon_greedy_solver = DecayingEpsilonGreedy(bandit_10_arm)
# decaying_epsilon_greedy_solver.run(5000)
# print('epsilon 值衰减的贪婪算法的累积懊悔为:', decaying_epsilon_greedy_solver.regret)
# plot_results([decaying_epsilon_greedy_solver], ["DecayingEpsilonGreedy"])
# # epsilon 值衰减的贪婪算法的累积懊悔为:10.114334931260183
# # 4.上置信界算法
# np.random.seed(1)
# coef = 1 # 控制不确定性比重的系数
# UCB_solver = UCB(bandit_10_arm, coef)
# UCB_solver.run(5000)
# print('上置信界算法的累积懊悔为:', UCB_solver.regret)
# plot_results([UCB_solver], ["UCB"])
# # 上置信界算法的累积懊悔为:4.360254345326592
# 5.普森采样算法
np.random.seed(1)
thompson_sampling_solver = ThompsonSampling(bandit_10_arm)
thompson_sampling_solver.run(5000)
print('汤普森采样算法的累积懊悔为: ', thompson_sampling_solver.regret)
plot_results([thompson_sampling_solver], ["ThompsonSampling"])
# 汤普森采样算法的累积懊悔为: 57.19161964443925
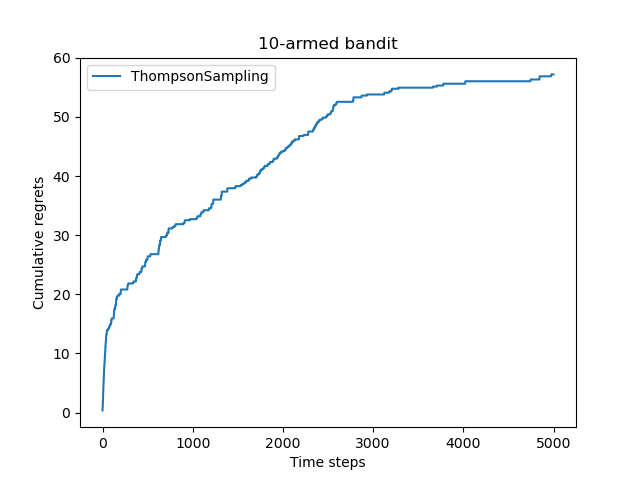
对比几种算法,ε -贪婪算法的累积懊悔是随时间线性增长的,而另外 3种算法(ε -衰减贪婪算法、上置信界算法、汤普森采样算法)的累积懊悔都是随时间次线性增长的(具体为对数形式增长)。
三、马尔可夫决策过程¶
学习目标:
1.理解随机过程、马尔可夫性
2.知道马尔可夫决策过程五元组
3.1 简介¶
马尔可夫决策过程(Markov decision process,MDP)是强化学习的重要概念。要学好强化学习,我们首先要掌握马尔可夫决策过程的基础知识。
与多臂老虎机问题不同,马尔可夫决策过程包含状态信息以及状态之间的转移机制。如果要用强化学习去解决一个实际问题,第一步要做的事情就是把这个实际问题抽象为一个马尔可夫决策过程,也就是明确马尔可夫决策过程的各个组成要素。
3.2 随机过程¶
随机过程(stochastic process)是概率论的“动力学”部分,研究对象是随时间演变的随机现象(例如天气随时间的变化、城市交通随时间的变化)。
在随机过程中,随机现象在某时刻t 的取值是一个向量随机变量,用\(\mathcal{S}_{t}\)表示。之所以是向量随机变量,是考虑了数学定义的通用性以及真实世界的复杂性。以天气为例,天气不止有气温,而是一个多维系统,例如:
\(S_t = \begin{bmatrix} \text{温度} \\ \text{湿度} \\ \text{气压} \\ \text{风速} \end{bmatrix} = \begin{bmatrix} 25^\circ\text{C} \\ 60\% \\ 101\text{kPa} \\ 3\text{m/s} \end{bmatrix}\)
随机过程的核心不仅在于“随机”,更在于“过程”。时刻 \(t\) 的状态通常不仅仅取决于当前的随机性,还往往依赖于系统之前的历史状态。 为了量化这种依赖关系,在离散时间的情况下,我们关注在已知历史信息 \((S_1, S_2, \dots, S_t)\) 的条件下,下一时刻状态为 \(S_{t+1}\) 的条件概率,即:
\(P(S_{t+1} \mid S_1, S_2, \dots, S_t)\)
这便是我们分析随机过程动力学特征的基础。
3.3 马尔可夫性质¶
当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质(Markov property),用公式表示为:\(P(\boldsymbol{S}_{t+1} \mid \boldsymbol{S}_t) = P(\boldsymbol{S}_{t+1} \mid \boldsymbol{S}_1, \cdots, \boldsymbol{S}_t)\)。即下一刻状态只取决于当前状态,而不会受到过去状态的影响。
需要明确的是,具有马尔可夫性质并不代表这个随机过程就和历史完全没有关系。因为虽然t +1时刻的状态只与t 时刻的状态有关,但是t 时刻的状态其实包含了t −1时刻的状态的信息,通过这种链式的关系,历史的信息被传递到了现在。马尔可夫性质可以大大简化运算,因为只要当前状态可知,所有的历史信息就都不再需要了,利用当前状态的信息就可以决定未来。
3.4 马尔可夫决策过程¶
马尔可夫决策过程由五元组\(\langle \mathcal{S}, \mathcal{A}, P, r, \gamma \rangle\) 构成,其中:
- \(\mathcal{S}\)是状态的集合
- \(\mathcal{A}\)是动作的集合
- \(\gamma\)是折扣因子
- \(r(\boldsymbol{s}, \boldsymbol{a})\)是奖励函数,此时奖励可以同时取决于状态\(\boldsymbol{s}\)和动作\(\boldsymbol{a}\)
- \(P(s'\mid s, \boldsymbol{a})\)是状态转移函数,表示在状态\(\boldsymbol{s}\) 执行动作\(\boldsymbol{a}\)之后到达状态\(s'\)的概率。这里我们不再使用类似 MRP 定义中的状态转移矩阵,而是直接使用状态转移函数。这样做一是因为此时的状态转移与动作也有关,变成了一个三维数组,而不再是一个矩阵(二维数组);二是因为状态转移函数更具有一般意义,例如,如果状态集合不是有限的,就无法用数组表示,但仍然可以用状态转移函数表示。
下图是一个马尔可夫决策过程的简单例子,其中每个深色圆圈代表一个状态,一共有 s1~s5 这 5 个状态。黑色实线箭头代表可以采取的动作,浅色小圆圈代表动作,需要注意,并非在每个状态下都能采取所有动作,例如在状态 s1,智能体只能采取“保持 s1”和“前往 s2”这两个动作,无法采取其他动作。 每个浅色小圆圈旁的数字代表在某个状态下采取某个动作能获得的奖励。虚线箭头代表采取动作后可能转移到的状态,箭头边上的数字代表转移概率,如果没有数字则表示转移概率1。例如:在 s2下,如果采取动作“前往 s3”,就能得到奖励−2,并且转移到 s3;在 s4下,如果采取“概率前往”,就能得到奖励 1,并且会分别以概率 0.2、0.4、0.4 转移到 s2、s3或 s4。
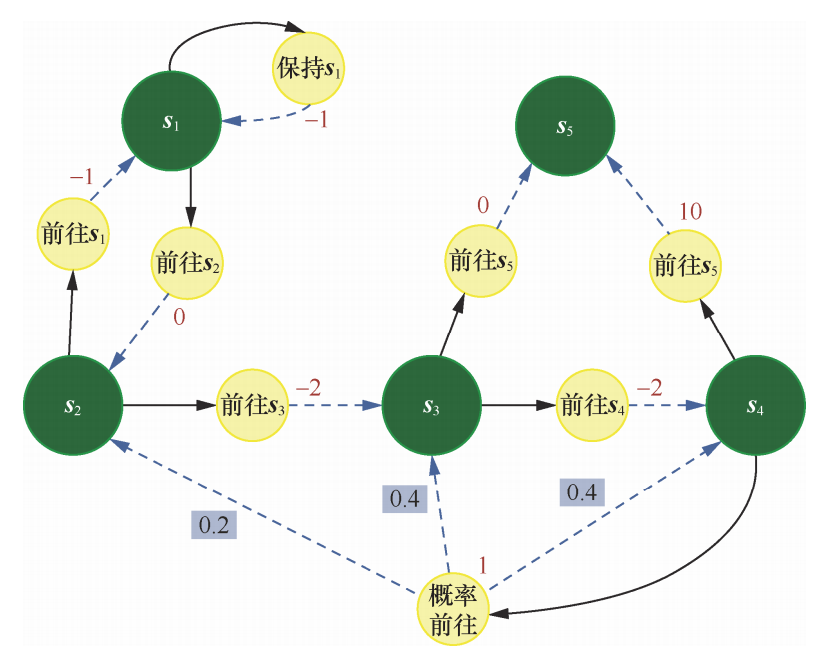
马尔可夫决策过程的五元组为强化学习提供了结构化建模框架,将环境动态、智能体决策与长期目标统一于随机过程。
马尔可夫决策过程是一个与时间相关的不断进行的过程,在智能体和环境 MDP 之间存在一个不断交互的过程。一般而言,它们之间的交互如下图所示:
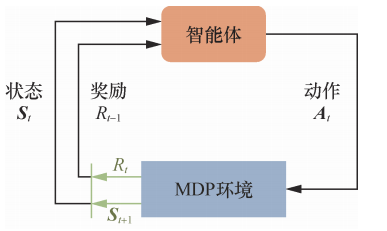
智能体根据当前状态 \(\mathcal{S}_{t}\)选择动作 \(\mathcal{A}_{t}\);对于状态 \(\mathcal{S}_{t}\)和动作 \(\mathcal{A}_{t}\) ,MDP根据奖励函数和状态转移函数得到 \(\mathcal{S}_{t+1}\)和\(\mathcal{R}_{t}\) 并反馈给智能体。智能体的目标是最大化得到的累积奖励的期望。
四、贝尔曼方程¶
学习目标:
1.理解状态价值、动作价值
2.知道贝尔曼方程的形式与含义
3.理解最优策略,知道贝尔曼最优方程的形式与含义
4.知道强化学习训练的目标
4.1 状态价值¶
状态价值是指在给定状态下,智能体根据当前策略从该状态出发所能获得的预期累积奖励。
解释如下:
考虑一系列时间步 \(t = 0, 1, 2, \dots\)。在时间 \(t\),智能体处于状态 \(S_t\),遵循策略 \(\pi\) 采取的动作是 \(A_t\)。下一个状态是 \(S_{t+1}\),获得的即时奖励是 \(R_{t+1}\)。这个过程可以简明地表示为:
注意 \(S_t, S_{t+1}, A_t, R_{t+1}\) 都是随机变量。此外,\(S_t, S_{t+1} \in \mathcal{S}, A_t \in \mathcal{A}(S_t)\),且 \(R_{t+1} \in \mathcal{R}(S_t, A_t)\)。
从 \(t\) 开始,我们可以获得一个状态-动作-奖励轨迹:
根据定义,沿该轨迹的折扣回报是
其中 \(\gamma \in (0, 1)\) 是折扣率,等号上方一个点表示定义为,在教科书或论文中,当看到 ≐时,要立刻意识到:“这是一个重要的定义,我需要记住它,因为后续的推导和讨论都基于此。
注意 \(G_t\) 是一个随机变量,因为 \(R_{t+1}, R_{t+2}, \dots\) 都是随机变量。由于 \(G_t\) 是一个随机变量,我们可以计算它的期望值(也称为期望或均值):
这里,\(v_{\pi}(s)\) 被称为状态价值函数(state-value function)或简称 \(s\) 的状态价值(state value)。以下给出一些重要的说明。
- \(v_{\pi}(s)\) 依赖于 \(s\)。这是因为它的定义是一个条件期望,条件是智能体从 \(S_t = s\) 开始。
- \(v_{\pi}(s)\) 依赖于 \(\pi\)。这是因为轨迹是遵循策略 \(\pi\) 生成的。对于不同的策略,状态价值可能会不同。
- \(v_{\pi}(s)\) 不依赖于 \(t\)。如果智能体在状态空间中移动,\(t\) 代表当前时间步。一旦给定了策略,\(v_{\pi}(s)\) 的值也就确定了。
状态价值和回报之间的关系进一步阐明如下。当策略和系统模型都是确定性的时候,从一个状态出发总是导致相同的轨迹。在这种情况下,从一个状态出发获得的回报等于该状态的价值。相比之下,当策略或系统模型是随机的时候,从同一状态出发可能会产生不同的轨迹。在这种情况下,不同轨迹的回报是不同的,而状态价值是这些回报的均值。
4.2 动作价值¶
动作价值是指在给定状态下,采取某个特定动作并按照当前策略继续执行所能获得的预期累积奖励。
动作价值考虑了采取具体动作后的奖励,而状态价值则是考虑了整体状态下的奖励预期。
动作价值定义为
可以看出,动作价值定义为在某个状态采取某个动作后可以获得的预期回报。必须注意,\(q_{\pi}(s, a)\) 依赖于状态-动作对 \((s, a)\) 而不仅仅是动作。称其为状态-动作价值可能更严谨,但为了简单起见,通常称其为动作价值。
动作价值和状态价值之间有什么关系?
根据条件期望的性质可得
随之得出
结果是,状态价值是与该状态关联的动作价值的期望。
4.3 贝尔曼方程¶
贝尔曼方程是一个用于分析状态价值的数学工具,也是强化学习的理论核心。具体来说,贝尔曼方程是一组线性方程,描述了所有状态价值之间的关系。
4.3.1 贝尔曼方程的推导¶
首先,注意 \(G_t\) 可以重写为
其中 \(G_{t+1} = R_{t+2} + \gamma R_{t+3} + \dots\)。这个方程建立了 \(G_t\) 和 \(G_{t+1}\) 之间的关系。然后,状态价值可以写为
下面分析 (1.1) 中的两项。
- 第一项 \(\mathbb{E}[R_{t+1} | S_t = s]\) 是即时奖励的期望。利用全期望公式,可以计算为
\(\begin{aligned} \mathbb{E}[R_{t+1} | S_t = s] &= \sum_{a \in \mathcal{A}} \pi(a|s) \mathbb{E}[R_{t+1} | S_t = s, A_t = a] \\ &= \sum_{a \in \mathcal{A}} \pi(a|s) \sum_{r \in \mathcal{R}} p(r|s, a) r. \quad (1.2) \end{aligned}\)
这里,\(\mathcal{A}\) 和 \(\mathcal{R}\) 分别是可能的动作和奖励的集合。需要注意的是,对于不同的状态,\(\mathcal{A}\) 可能是不同的。在这种情况下,\(\mathcal{A}\) 应写作 \(\mathcal{A}(s)\)。同样,\(\mathcal{R}\) 也可能依赖于 \((s, a)\)。为了简化,这里省略了对 \(s\) 或 \((s, a)\) 的依赖。尽管如此,在存在依赖关系的情况下,结论仍然有效。
- 第二项 \(\mathbb{E}[G_{t+1} | S_t = s]\) 是未来奖励的期望。可以计算为
\(\begin{aligned} \mathbb{E}[G_{t+1} | S_t = s] &= \sum_{s' \in \mathcal{S}} \mathbb{E}[G_{t+1} | S_t = s, S_{t+1} = s'] p(s'|s) \\ &= \sum_{s' \in \mathcal{S}} \mathbb{E}[G_{t+1} | S_{t+1} = s'] p(s'|s) \quad (\text{由于马尔可夫性质}) \\ &= \sum_{s' \in \mathcal{S}} v_{\pi}(s') p(s'|s) \\ &= \sum_{s' \in \mathcal{S}} v_{\pi}(s') \sum_{a \in \mathcal{A}} p(s'|s, a) \pi(a|s). \quad (1.3) \end{aligned}\)
上述推导利用了 \(\mathbb{E}[G_{t+1} | S_t = s, S_{t+1} = s'] = \mathbb{E}[G_{t+1} | S_{t+1} = s']\) 这一事实,这是由于马尔可夫性质,即未来奖励仅依赖于当前状态而不是之前的状态。
将 (1.2)-(1.3) 代入 (1.1) 得到
\(\begin{aligned} v_{\pi}(s) &= \mathbb{E}[R_{t+1} | S_t = s] + \gamma \mathbb{E}[G_{t+1} | S_t = s] \\ &= \underbrace{\sum_{a \in \mathcal{A}} \pi(a|s) \sum_{r \in \mathcal{R}} p(r|s, a) r}_{\text{即时奖励的均值}} + \underbrace{\gamma \sum_{a \in \mathcal{A}} \pi(a|s) \sum_{s' \in \mathcal{S}} p(s'|s, a) v_{\pi}(s')}_{\text{未来奖励的均值}} \\ &= \sum_{a \in \mathcal{A}} \pi(a|s) \left[ \sum_{r \in \mathcal{R}} p(r|s, a) r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s, a) v_{\pi}(s') \right], \quad \text{对于所有 } s \in \mathcal{S}. \quad (1.4) \end{aligned}\)
这个方程就是著名的贝尔曼方程,它刻画了状态价值之间的关系。它是设计和分析强化学习算法的基本工具。
贝尔曼方程乍一看似乎很复杂。事实上,它有一个清晰的结构。以下给出一些说明。
- \(v_{\pi}(s)\) 和 \(v_{\pi}(s')\) 是待计算的未知状态价值。初学者可能会对如何计算未知的 \(v_{\pi}(s)\) 感到困惑,因为它依赖于另一个未知的 \(v_{\pi}(s')\)。必须注意,贝尔曼方程指的是针对所有状态的一组线性方程,而不是单个方程。如果我们把这些方程放在一起,就可以计算所有状态价值了。
- \(\pi(a|s)\) 是给定的策略。由于状态价值可以用来评估策略,从贝尔曼方程中求解状态价值是一个策略评估过程,这是许多强化学习算法中的一个重要过程。
- \(p(r|s, a)\) 和 \(p(s'|s, a)\) 代表系统模型。可以在有这个模型时计算状态价值,也可以使用无这个模型算法在没有模型的情况下计算。对应着强化学习的有模型算法(动态规划、Dyna-Q)与无模型算法(主流是无模型:Q-learning、SARSA、DQN、策略梯度方法、A2C、PPO、TRPO、GRPO等)。
在(1.4) 中的表达式基础上重写一下,贝尔曼方程可以简写成如下形式:
\(v_{\pi}(s) = \sum_{a \in \mathcal{A}} \pi(a|s)[r_{\pi}(s,a) + \gamma \sum_{s' \in \mathcal{S}} p_{\pi}(s'|s,a) v_{\pi}(s')], \quad (1.5)\)
其中
\(r_{\pi}(s,a) \doteq \sum_{r \in \mathcal{R}} p(r|s, a) r,\)
这里,\(r_{\pi}(s)\) 表示即时奖励的均值,\(p_{\pi}(s'|s)\) 是在策略 \(\pi\) 下从 \(s\) 转移到 \(s'\) 的概率。
以上是状态价值的贝尔曼方程。
那么根据状态价值与动作价值的关系:$$ v_{\pi}(s) = \sum_{a \in \mathcal{A}} \pi(a|s) q_{\pi}(s, a)$$
状态价值由1.4式给出 $$ v_{\pi}(s) = \sum_{a \in \mathcal{A}} \pi(a|s) \left[ \sum_{r \in \mathcal{R}} p(r|s, a) r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s, a) v_{\pi}(s') \right], $$
可得动作价值的贝尔曼方程: $$ q_{\pi}(s, a) = \sum_{r \in \mathcal{R}} p(r|s, a) r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s, a) v_{\pi}(s'). \quad (1.6) $$
4.4 贝尔曼最优方程¶
4.4.1 最优策略¶
强化学习的最终目标是获得最优策略,但首先必须定义什么是最优策略。该定义基于状态价值。特别地,考虑两个给定的策略 \(\pi_1\) 和 \(\pi_2\)。如果 \(\pi_1\) 的状态价值在任何状态下都大于或等于 \(\pi_2\) 的状态价值: $$ v_{\pi_1}(s) \ge v_{\pi_2}(s), \quad \text{对于所有 } s \in \mathcal{S}, $$ 则称 \(\pi_1\) 优于 \(\pi_2\)。此外,如果一个策略优于所有其他可能的策略,则该策略是最优的。
最优策略和最优状态价值): 如果一个策略 \(\pi^*\) 对所有 \(s \in \mathcal{S}\) 以及任何其他策略 \(\pi\) 都满足 \(v_{\pi^*}(s) \ge v_{\pi}(s)\),则称该策略 \(\pi^*\) 是最优的。\(\pi^*\) 的状态价值即为最优状态价值。
上述定义表明,与所有其他策略相比,最优策略在每个状态都具有最大的状态价值。这个定义也引出了许多问题:
- 存在性: 最优策略是否存在?——>存在。最优策略总是存在的。
- 唯一性: 最优策略是唯一的吗?——>不一定。可能存在多个或无限个具有相同最优状态价值的最优策略。
- 随机性: 最优策略是随机的还是确定性的?——>最优策略既可以是确定性的,也可以是随机的。
- 算法: 如何获得最优策略和最优状态价值?——>通过一些强化学习算法。
4.4.2 贝尔曼最优方程¶
分析最优策略和最优状态价值的工具是贝尔曼最优方程(Bellman Optimality Equation, BOE)。通过求解这个方程,我们可以获得最优策略和最优状态价值。接下来我们给出 BOE 的表达式并详细分析它。
对于每个 \(s \in \mathcal{S}\),BOE 的逐元素表达式为
\(\begin{aligned} v(s) &= \max_{\pi(s) \in \Pi(s)} \sum_{a \in \mathcal{A}} \pi(a|s) \left( \sum_{r \in \mathcal{R}} p(r|s, a)r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s, a)v(s') \right) \\ &= \max_{\pi(s) \in \Pi(s)} \sum_{a \in \mathcal{A}} \pi(a|s) q(s, a), \quad (1.11) \end{aligned}\)
其中 \(v(s), v(s')\) 是待求解的未知变量,且
\(q(s, a) \doteq \sum_{r \in \mathcal{R}} p(r|s, a)r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s, a)v(s')\)
这里,\(\pi(s)\) 表示针对状态 \(s\) 的策略,\(\Pi(s)\) 是 \(s\) 的所有可能策略的集合。
从这里可以看出,BOE 实际上是一种特殊的贝尔曼方程。
4.5 强化学习训练的目标¶
强化学习的终极目标是训练一个能够在特定环境中通过与环境持续交互,最终学会做出长期最优决策的智能体。
具体来说,训练过程致力于实现以下几点:
- 学习最优策略: 策略定义了智能体在不同状态下应该采取什么动作。训练的目的是找到一个策略(函数),使得当智能体遵循这个策略时,它能获得最大的长期累积奖励。
- 最大化累积奖励: 这是最核心的目标。智能体不是追求单次动作的即时奖励最大化,而是追求在整个任务过程中(可能是一个漫长的序列)获得的总奖励(可能带有折扣因子)最大化。训练就是要调整智能体的决策方式,使其朝着这个总奖励最大的方向前进。
- 理解环境: 在训练过程中,智能体通过与环境的交互(尝试动作 -> 观察新状态和奖励),不断地学习和更新它对环境的理解。在“基于模型”的强化学习中,智能体会显式地学习环境的状态转移动态和奖励函数;在更主流的“无模型”强化学习中,智能体则直接学习基于经验的价值函数或策略。
- 平衡探索与利用: 训练过程需要智能体有效地管理一个关键矛盾:是探索未知的状态和动作(可能发现高回报的新区域)还是利用当前已知的最佳动作(获取已知的较高奖励)。一个好的训练算法能引导智能体在两者之间找到有效平衡。
- 泛化到未见状态: 训练不仅希望智能体在见过的状态下表现好,更希望它能在训练中从未遇到但相似的状态下也能做出合理、甚至是最优的决策(尤其是在状态空间巨大或连续时)。
就像一个训练狗学习新把戏的过程。目的是让狗学会一整套动作(比如接飞盘),使得在抛出飞盘(环境状态)后,它能正确执行一系列动作(跑位、跳跃、叼住)并最终获得最大的奖励(狗粮和夸奖)。训练过程就是通过不断尝试(探索不同跑位角度)和奖励反馈(成功叼住就奖励,没叼住就没奖励/轻微惩罚),最终让它掌握最优的“接飞盘策略”。
作业¶
1.完成强化学习入门的思维导图
2.说明强化学习的流程
3.说一下强化学习中的探索和利用的平衡是什么意思
4.分别用ε -贪婪算法、上置信界算法、汤普森采样算法实现MAB问题
5.说明马尔可夫决策过程的五元组分别代表什么含义
6.说明状态价值与动作价值的含义
7.了解贝尔曼方程的推导